Recently, I dedicated 10 days to the Stanford FLAME AI Workshop: Future Learning Approaches for Modeling and Engineering. This event aimed to provide insights into the confluence of machine learning with fluid dynamics, turbulence, and combustion.
The workshop was a careful blend of expert talks and an engaging ML challenge. We had thought leaders like George Karniadakis from Brown University giving a lecture about “Physics-informed Neural Networks (PINNs) and Neural Operators” [Rai19P] [Kar21P] [DeepONet], Anima Anandkumar from Caltech and Nvidia who discussed “Neural Operators” [Li20F] [Pat22F], Stephan Hoyer from Google Research talking about “Deep Learning with Differentiable Physical for Fluid Dynamics and Weather Forecasting” [Lam23G], and Steve Brunton from the University of Washington sharing thoughts on “Machine Learning for Scientific Discovery” [Bru16D, Bru22D]. These sessions, among many others, have broadened my understanding of how intricate the relationship between fluid dynamics and AI can be.
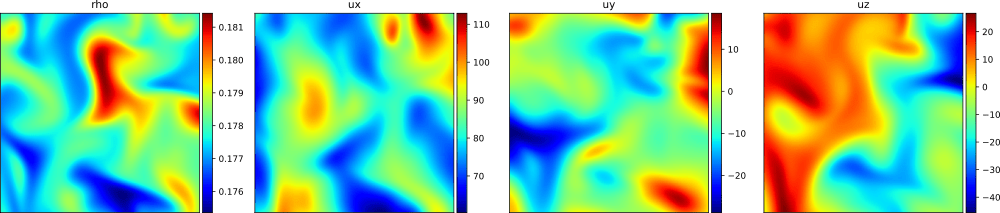
Figure 1. High-resolution image of turbulent flow simulation. Every sample is a slice of a three-dimensional domain and consists of four channels: density and velocties in x-, y-, and z-direction.
Diving Deeper: The ML Challenge
While the lectures were highly inspiring, the core of FLAME was its Kaggle ML challenge. It was structured around the idea of super-resolution in turbulent flows: image super-resolution (SR) addresses the inverse problem of reconstructing high-resolution (HR) images from their low-resolution (LR) counterparts, cf. [Lim17E]. With a data set consisting just over 1000 training samples of snapshots of turbulent flow simulations - taken from a structured data set [Chu22B] - participants had the task of scaling up images of only 16x16 pixels to high-resolution images of 128x128 pixels, which eventually helps to accelerate the simulation of turbulent flows.
The comparatively small dataset and the tight time constraints were a real challenge. I tried to apply physics-informed DeepONets to the problem, but unfortunately couldn’t get it to work within the deadline. In the end, my approach using a simple upscaling supplemented by some convolutional layers (see GitHub) scored the 10th position on the Kaggle leaderboard, and I’m happy to be invited towards a joint publication. Many other leading approches used modifcations of EDSR, a deep residual network architecture for image super-resolution, and the winning approach was based on a recently proposed super-resolution neural operator [Wei23S].
Personal Reflections on the Workshop
Being based in Munich and juggling a 9-hour time difference wasn’t easy, but my interest in the intersection of simulation and AI along with the exciting speakers and engaging challenge of this workshop made it worthwhile.
In all, FLAME 2023 was an enlightening experience: It deepened my understanding and fueled my passion in a field that already fascinates me, and it was a joy to connect with the vibrant community centered around simulation and AI. I look forward to future events of this kind!
