Concept bottleneck (CB) models [Koh20C] are a class of intrinsically interpretable models where each neuron in one or more layers of the neural network activate only when a specific human-understandable feature is present in the input. For example, in order to predict the species of a bird, in the last layer of a CB-CNN a neuron could be tasked to activate proportionally to how long the beak is, another could instead focus on the color of the wings, and so on (see Figure 1).
Together with being interpretable, CBs allow for test-time interventions, e.g. they allow an expert to actively lower or increase a neuron output to put emphasis on a particular feature. This has been shown to decrease spurious sample correlations and overall improve human-machine interaction and trust.
Nevertheless, to train these models, additional (concept) labels need to be provided, and the final performance typically does not match the accuracy of unrestricted black-box models. This has so far hindered the utilization of CBs in practice.
 Figure 1. Each activation in
the last layer of a concept bottleneck model is related to human understandable
concepts. These are then used for the final (interpretable) prediction. Image
from [Koh20C].
Figure 1. Each activation in
the last layer of a concept bottleneck model is related to human understandable
concepts. These are then used for the final (interpretable) prediction. Image
from [Koh20C].The recent paper [Yuk23P] proposes a way to circumvent these limitations without modifying the architecture of a pre-trained model. First, one needs to calculate the concept activation vectors (CAVs) [Kim18I] in the model’s output subspace. More details on CAVs are available in our previous pill. When concept labels are not available, CAVs can be extracted directly from the text encoder of a text-to-image model (e.g. by passing the prompt “stripes” to CLIP) (Figure2, left).
On top of the pre-trained model a post-hoc CB layer is then added, together with a final interpretable predictor (e.g. a sparse linear layer). At inference, the output of the backbone is projected onto the concept vectors’ subspace, thus associating to each sample a set of human understandable features, which are then used for predictions. Despite the access to generative models, and no matter the number of concept used, the model may not match the performance of the unrestricted model. Thus, an additional (non-interpretable) residual can be fitted and then passed to the last layer (Figure 2, right).
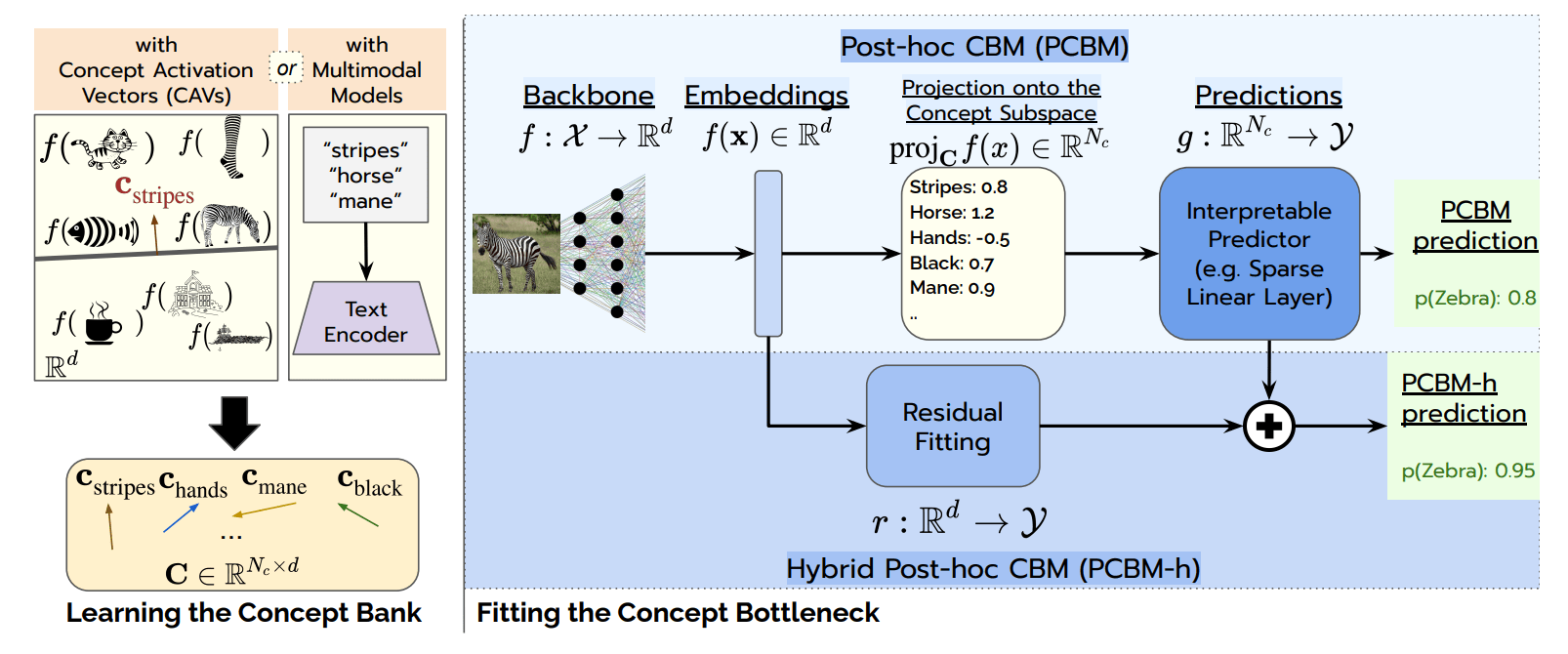
Figure 2. Post-hoc concept bottleneck models are trained in two phases. During the first, high level concept vectors are extracted through CAVs or multimodal models. Then a pre-trained model backbone is enhanced with two fully interpretable layers and an additinal non-interpretable residual which grants high accuracy. From [Yuk23P].
The experiments presented in the paper are encouraging. The performance of the
post-hoc CBs is quite good and often reach the original
pre-trained model. When using the residual predictor (PCBM-h) the performance
is always very close to the original (Figure 3). Figure 3. Performance of post-hoc concept
bottleneck models (PCBM) and their enhanced version (PCBM-h, i.e. with residual)
compared to the original black-box model in benchmark datasets. From [Yuk23P].
Even more interestingly, CB models can effectively be made more robust through human guidance. Section 4 of the paper presents a study where a model is given out-of-distribution images (e.g. all images with a keyboard also contain a cat in training set, but not in test set) and then humans are tasked to decontaminate the predictions through model editing of the concept layer. For all 30 trial users model editing improved average performance.
In summary, the access to generative multi-modal models and the use of hybrid post-hoc techniques could give the necessary push for new and accurate concept-based interpretable NNs. In addition, other approaches have emerged also to tackle the accuracy-explainability trade-off in CBs, with different techniques, e.g. using so called “concept embeddings” [Zar22C]. If any of these prove reliable in practice, they could become essential tools to audit and edit each model’s prediction, with interesting applications in the medical sector and more generally in all those high-stakes environments that require tight human supervision.
