Intermediate layers of neural networks have significant representational power that lies at the basis of all kinds of cool applications. One can use them to change the style of an image with neural style transfer, to create artificial images maximizing their activation via the deepdream algorithm, to perform semantic arithmetics with word and sentence embeddings and much more.
One of the invited talks of ICLR 2022 revolved around the recent developments of this fascinating research area. For example in [Kim18I] this representational power is employed for interpreting a neural network’s decisions through high-level human designed concepts. The main idea of the paper (dubbed TCAV for Testing with Concept Activation Vectors) can be formulated like this: find a direction (vector) in the same space as the activations of some intermediate layer $l$ that corresponds to a humanly understandable concept, e.g. “striped” or “male”. Then the corresponding directional derivative of the network’s output for a sample $x$ is a measure of sensitivity of the prediction to the selected concept. This directional derivative is found by computing the activations of the $l$-th layer for $x, f_l(x),$ and by taking the derivative of the remaining network’s output ($h_l, k$ in the image below) w.r.t. the concept’s direction at $f_l(x).$
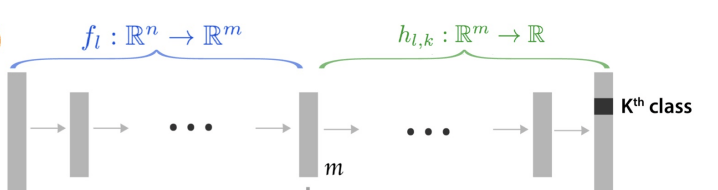
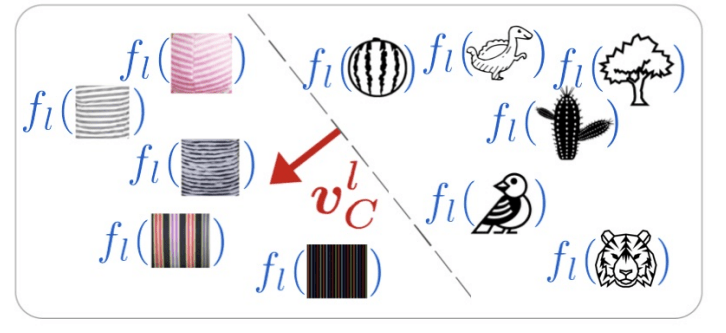
The paper proposes a simple and intuitive scheme for finding such directions
which they call concept activation vectors (CAV). A CAV is determined by a
user through providing several inputs corresponding to their concept of choice
together with “random” inputs not corresponding to this concept. Note that these
inputs don’t have to be part of the training set. First, activation vectors of
an intermediate layer $l$ are computed (the functions $f_l$ in the image below)
for all inputs. The direction in activation space orthogonal to the plane that
optimally separates concept activations from random input activations is the
desired concept activation vector. In practice, this direction can easily be
computed by fitting a linear binary classifier on the dataset given by
activation vectors and the corresponding is_concept = True/False labels. The
image below illustrates this procedure for finding a CAV for the concept
“striped”.
Once the CAV is determined, it can be used for a variety of tasks. In particular, the authors propose testing the sensitivity of predicting a class label $k$ w.r.t. to the selected concept by computing the fraction of datapoints belonging to this class in the training set where the directional derivative of the $k-th$ logit is positive, i.e. where a movement towards the concept corresponds to a higher probability of predicting $k$. One can thus check whether the concept red is important for predicting a fire truck or whether male is important for predicting doctor. This way of testing is dubbed TCAV. Apart from the author’s implementation, TCAV has also been integrated in pytorch’s model interpretation toolbox captum.ai.
CAVs can be used in a variety of ways, we recommend having a look at the follow-up papers by Been Kim for more details. In my personal opinion, this is a nice extension to the interpretability toolbox but it should be used with caution as the CAVs are computed from human inputs and heavily depend on the negative “random” counterexamples. E.g. the concept of male may easily be mistaken by the concept of human with suit if the user is not careful enough in their choice of counterexamples.
