An outlier is an observation that deviates so much from other observations as to arouse suspicion that it was generated by a different mechanism
Hawkins [Haw80I]
About the workshop
Detecting anomalies is of high interest in multiple industries for identifying safety and security risks, ensuring production quality, or finding new business opportunities. However, anomaly detection faces some unique challenges. First, identifying anomalies by hand is difficult, especially in multidimensional data. Second, anomalies are usually poorly represented in datasets.
 Anomaly detection in predictive maintenance can prevent system failures(image source)
Anomaly detection in predictive maintenance can prevent system failures(image source)Anomaly detection must therefore rely largely on unsupervised learning with possibly contaminated nominal data. These methods need additional assumptions about the data to be able to identify anomalies reliably. In this workshop, we will review common approaches for anomaly detection and discuss their strengths and weaknesses in different application areas.
We published the material for this workshop on GitHub, which includes a Codespace to start with the content right away. Furthermore, we’ve recorded the training and published it on our Learning Platform as well as YouTube.
To get the most of the training, we recommend to book an iteration of the training on the top of this page. This setup includes regular discussions with our experts on the topic. Feel free to discuss recent research and personal projects in addition to the training’s content.
Learning outcomes
- Understanding qualitative and quantitative definitions of anomalies.
- Overview of theoretical foundations and practical implementations of multiple anomaly detection algorithms.
- Understand which algorithms are suitable for which application areas.
- Learn how to evaluate and compare performances of different algorithms.
- Learn to find thresholds for anomaly detection using extreme value theory.
Structure of the workshop
Part 1: Introduction to anomaly detection
We start with a brief introduction to anomaly detection and its applications. We discuss the special
challenges of anomaly detection and the different types of anomalies. We then
introduce the contamination framework.
Finally, we introduce evaluation metrics for anomaly detection and discuss the class imbalance problem.
Evaluation metrics for anomaly detection. Visualization of “few, sparse, different” assumption under the contamination framework
Visualization of “few, sparse, different” assumption under the contamination framework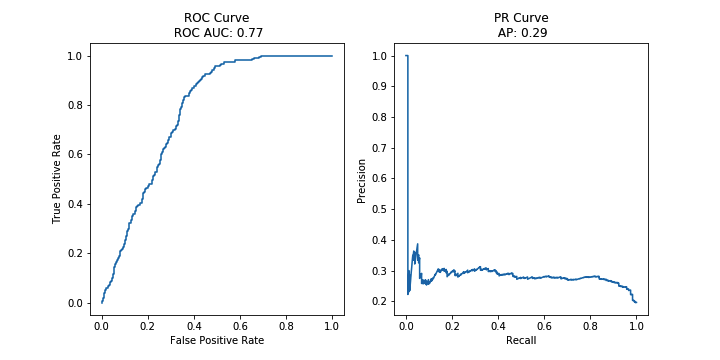
- The informal notion of anomaly and definition attempts.
- The contamination framework.
- Class imbalance.
- Evaluation metrics.
- Mahalanobis distance.
Part 2: Anomaly detection via density estimation and robustness
Density estimation is a common approach for anomaly detection. It rests on the
assumption that anomalies appear in unlikely areas of the feature space. We
discuss the Kernel density estimation (KDE) algorithm as a generic example of a
density estimation method. When the training data might contain unrecognized
anomalies, robustness is an important property of the estimation procedure. We
discuss robust variants of KDE and apply them to a real-world dataset
with mislabelled data.
 Kernel density estimation (image source)
Kernel density estimation (image source)
- Kernel density estimation.
- Robust variants of kernel density estimation.
- Example: Housing prices and mislabelled data.
Part 3: Anomaly detection via isolation
The isolation forest algorithm is a tree-based approach for anomaly detection.
It is based on the assumption that anomalies are rare and isolated. It has
drawn a lot of attention in the last years and is considered a state-of-the-art
algorithm for anomaly detection with excellent performance across a multitude of
benchmarks. We use the isolation forrest for network intrusion detection in the KDD99 dataset.
Isolation depth of a nominal point (green) and an anomaly (red) in an isolation tree Partition diagram of an isolation tree
Partition diagram of an isolation tree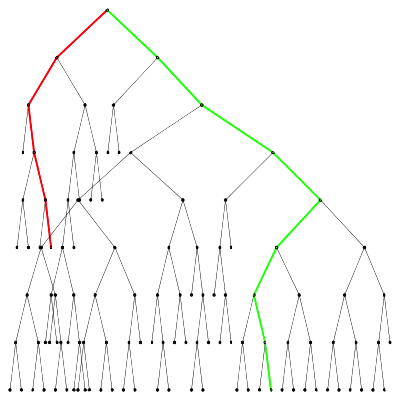
- Isolation Forrest.
- Example: Network intrusion detection with KDD99 dataset.
Part 4: Anomaly detection via reconstruction error
Anomaly detection is particularly challenging when the data is high-dimensional.
The previously introduced methods suffer from the curse of dimensionality and
usually quickly degrade in performance as the dimension rises above a couple dozens.
Auto-encoders are a class of neural networks that can be used to learn a
representation of the data that is more compact than the original data.
Auto-encoders can be used to detect anomalies by comparing the reconstruction
error of the original data with the reconstruction error of the anomalous data.
We apply auto-encoders to the MNIST dataset to detect corrupted images.
Auto-encoder reconstruction error Schematic view of an auto-encoder
Schematic view of an auto-encoder
- Auto-encoders
- Example: Identify corrupted images in the MNIST dataset.
Part 5: Anomaly detection in time series
Time series are a special type of data that is often used in anomaly detection.
We discuss the challenges of anomaly detection in time series and give a bit
of background in time series analysis that is useful for anomaly detection.
We then introduce
the SARIMA model as a simple forecasting model that can be used to detect
anomalies in time series. Finally, we apply the SARIMA model to the New York
taxi dataset to detect anomalies in the number of taxi rides. Anomaly detection in time series with SARIMA
- Introduction to time series analysis.
- Anomaly types: Point, context and pattern anomalies.
- Preprocessing techniques for anomaly detection in time series.
- Anomaly detection via forecasting error: SARIMA models.
- Example: Detecting anomalies in New York taxi data.
Part 6: Extreme value theory and GEV distributions
Most anomaly detection methods return a score for each data point. The score
indicates how anomalous a point is. However, the algorithms usually
do not provide thresholds for classifying a point as anomalous. We introduce
extreme value theory (EVT) as a method for finding thresholds for anomaly
detection. EVT is based on the assumption that the scores of anomalous points
are significantly higher than the scores of nominal points. It estimates the tail
of the score distribution and uses this to find a probabilistically interpretable
threshold. We apply EVT to the New York taxi dataset to find a threshold for
detecting anomalies in the number of taxi rides.
Fitting a GEV distribution Peaks over threshold method
Peaks over threshold method
- Relevance of EVT for anomaly detection.
- GEV distributions.
- Fitting GEV distributions.
- Example: Find detection threshold for anomalies in New York taxi data.
Prerequisites
- We assume some prior exposure to machine learning and the underlying concepts.
- Basic knowledge of Python is required to complete the exercises.

{kind=link}