About the workshop
Safety and reliability concerns are major obstacles for the adoption of AI in practice. In addition, European regulation will make explaining the decisions of models a requirement for so-called high-risk AI applications.
When models grow in size and complexity they tend to become less interpretable. Explainability in machine learning attempts to address this problem by providing insights into the inference process of a model. It can be used as a tool to make models more trustworthy, reliable, transferable, fair, and robust. However, it is not without its own problems, with algorithms often reporting contradictory explanations for the same phenomena.
This workshop provides an overview of the state-of-the-art in explainable AI, with a focus on practical considerations. We discuss different approaches to explainability, their strengths and weaknesses, and how they can be integrated into the machine learning pipeline. We also discuss the challenges of explainability in the context of deep learning and present interpretable deep-learning architectures for important domains such as computer vision and forecasting.
Learning outcomes
- Get an overview about the potential applications of explainability in machine learning.
- Get to know taxonomy of explainability methods and their applicability to different types of models.
- Learn how explainability considerations can be integrated into the machine
learning pipeline: Exploratory data analysis, feature engineering, model
selection, evaluation, visualization, and interpretation.
![]()
![Exploratory data analysis]() Exploratory data analysis
Exploratory data analysis - Get to know model agnostic and model specific explainability methods.
- Understand the difference between black-box explanations and intrinsically interpretable models.
- Learn about specialized techniques for important subfields such as time series forecasting or computer vision.
- Learn how to evaluate the quality of explanations.

Contents
Part 1: Introduction to explainable AI
We start the workshop with a gentle introduction into the topic of explainable
AI. We discuss the motivation for explainability, the different types of
explanations, and the challenges of explainability. Taxonomy of XAI methods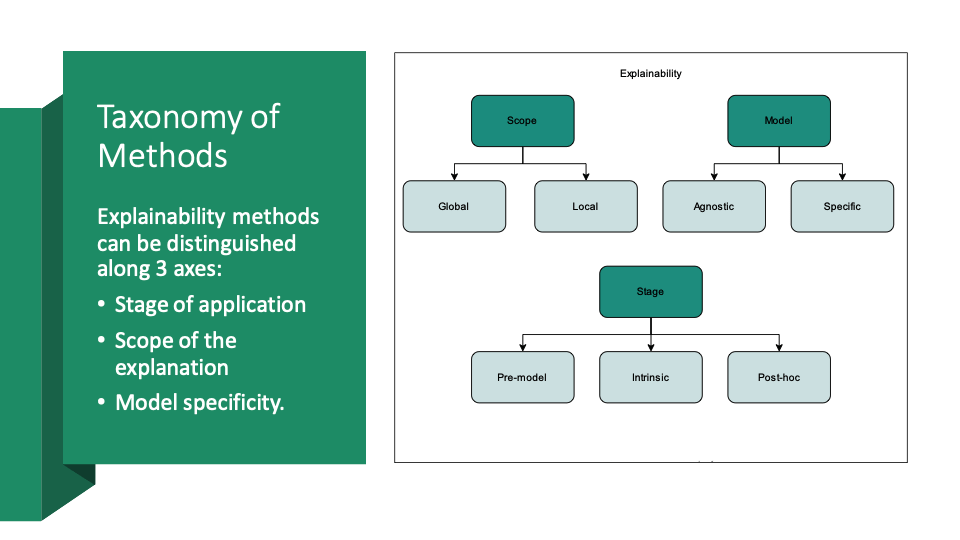
- AI incidents and the need for explainability
- Trust in AI
- Overview and taxonomy of explainability methods
- Intrinsically interpretable models and black box explanations
Part 2: Post-hoc explainability methods
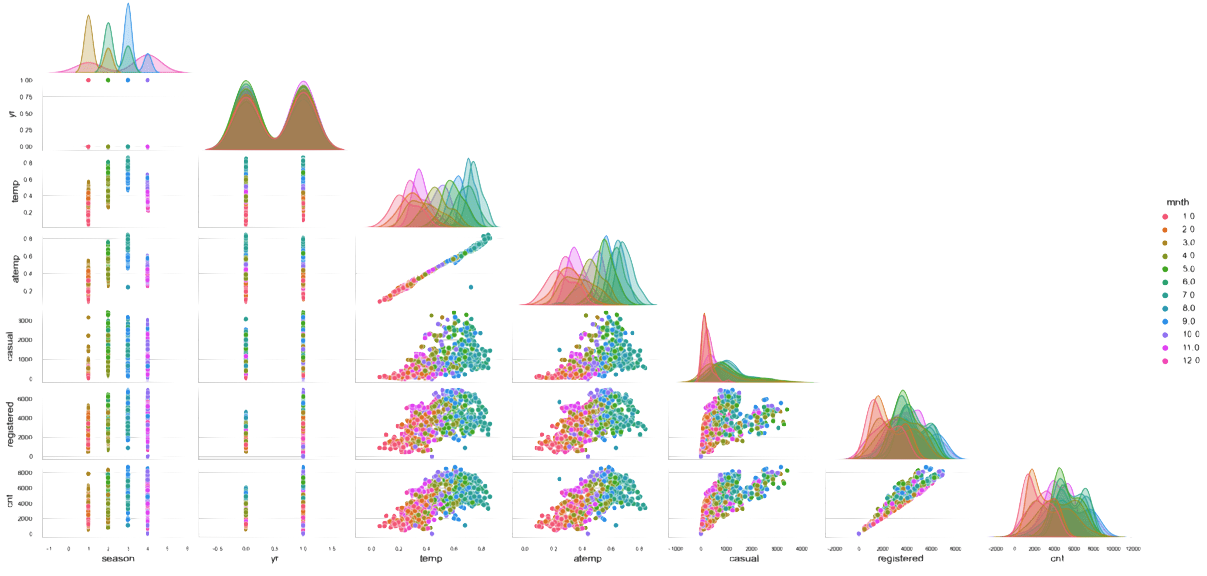
Most machine learning models today are not intrinsically interpretable. Model
agnostic post-hoc explainability methods try to provide insights into the
decision process of a model with considering its internal structure. Most
current approaches produce feature attributions, which are a measure of how much
each feature contributes to the prediction. Explanations of this kind have special
implications for the feature engineering process. We exemplify such
considerations on a bike rental prediction example. Concerning the
explainability methods, we present two important subclasses: Statistical
approaches (e.g. partial dependence and accumulated local effects) and local
surrogate models (e.g. LIME and SHAP). We discuss the different interpretations
of feature attribution as well as their strengths and weaknesses. Summary posthoc explanations
 Shap additive explanations
Shap additive explanations
- Partial dependence, individual conditional expectation, and accumulated local effects
- Additive explanations: LIME, Shapley values, and SHAP
Part 3: Deep learning specific methods
Deep learning models are often more complex than traditional machine learning
models. They are usually composed of many layers and have millions of
parameters. This makes them hard to understand. However, neural networks are
differentiable, which allows the use of gradient-based methods to understand
their predictions.
Saliency maps are among the most popular methods to understand the predictions
of deep learning models. They use the gradient of the output with respect to the
input to identify the most important features of the input. Another line of
research is to use the gradient of the loss with respect to a weighting of the
training data to determine the importance of a training point for the performance
of the model.
In particular, we apply gradient based methods to identify unhelpful data points
in a dataset and to understand the predictions of pre-built image classifiers.
 Saliency map via integrated gradients
Saliency map via integrated gradients
- Data valuation: influence functions
- Saliency maps
Part 4: Interpretable computer vision
Computer vision has long been a field of AI were it was commonly believed that one
needs to sacrifice interpretability for performance. However, recent advances in
explainable AI have shown that this is not necessarily the case. We will discuss
the recently proposed class of interpretable prototype networks. We evaluate their
performance on a bird classification task and discuss the extent to which they
are interpretable.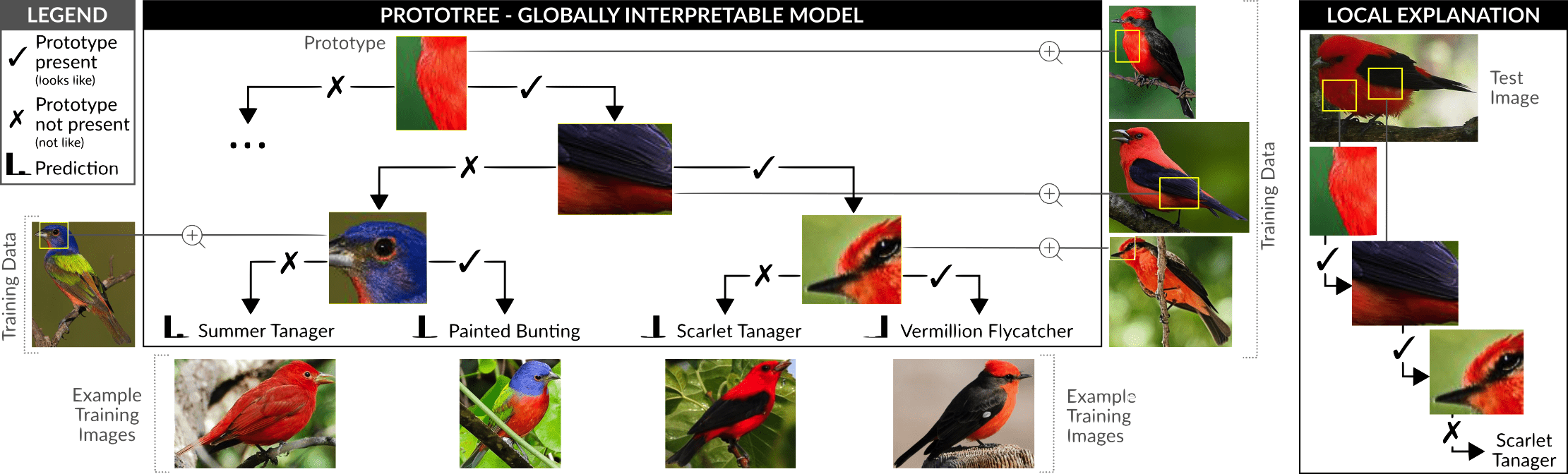
- Prototypes
- Transferlab ProtoTreeNet library
Part 5: Interpretable time series forecasting
Interpretability plays an important role in time series forecasting. Since
predictions are made about an intrinsically uncertain future, it is important to
understand the reasons for a prediction.
If an interpretable model accurately captures causalities in the data, it can
provide insights to analysts that work with forecasting models.
For the very same reasons, correct quantification of
uncertainty is of great importance for the proper interpretability of a
forecast.
We will discuss interpretable
probabilistic forecasting models as well as interpretable deep learning
architectures like attention based transformers.
We work under the analyst in the loop approach and
apply interpretable models to predict the price on the spanish electricity market.
Finally, we draw insights about the market from our models.
Quantile prediction of a transformer with attention map on the history Additive seasons-trend decomposition of a time series
Additive seasons-trend decomposition of a time series
- Prophet
- Neural hierarchical interpolation for time series forecasting
- Attention: Temporal Fusion Transformer
Prerequisites
- We assume prior exposure to machine learning and deep learning and a general understanding of the underlying mathematical concepts.
- Basic knowledge of Python is required to complete the exercises. Knowledge of
the python ML stack is recommended.
![Source: XKCD 2237]() Source: XKCD 2237
Source: XKCD 2237

Companion Seminar
Accompanying the course, we offer a seminar covering neighbouring topics that cannot make it into the course due to time constraints. It is held online over the course of several weeks and consists of talks reviewing papers in the field of explainable AI. The seminar is informal and open to everyone: we welcome participation, both in the discussions or presenting papers.
Acknowledgement goes to Faried Abu Zaid, Anes Benmerzoug, Michael Panchenko and Fabio Peruzzo for shaping the initial version of this training.
