Geometric deep learning is a field of machine learning that aims to incorporate geometric information into neural networks. In group equivariant machine learning, for instance, one builds networks which are equivariant or invariant under certain group actions that are applied to the input. The paper [Ruh23G] focuses on tasks where we can expect the target function to be a geometric transformation. Such functions arise naturally in the modeling of dynamical systems. The authors propose the framework of Clifford algebras, a major working horse of computational geometry, as basis to define geometric templates, which can be incorporated into neural network architectures and refined via gradient decent.
Clifford algebras
Real Clifford algebras (also called geometric algebras) are a generalization of the complex numbers and Quaternions that can be used to uniformly represent various geometric objects such as points, vectors, subspaces or even transformations, like reflections or isometries. Moreover, the algebraic operations are geometrically meaningful and allow to elegantly express many facts from linear algebra.
In an $n$-dimensional geometric algebra $CL_{p,q,r}(\mathbb{R})$, where $n=p+q+r$, one chooses $p$ positive, $q$ negative and $r$ null basis vectors $e_i$, where $e_ie_i\in\{-1, 0, 1\}$, $e_ie_j = -e_je_i$ and $e_i\lambda = \lambda e_i$, for $i\neq j$ and $\lambda\in\mathbb{R}$. A product of $k$ basis vectors $e_{i_1}\dots e_{i_k}=: e_{i_1\ldots i_k}$, where $i_k < i_\ell$ for $k<\ell$, is a basis k-blade where the grade of the blade is the dimension of the subspace it represents. Note that the defining equations ensure that we can write any product of basis vectors as a multiple of a basis blade. Hence, an $n$-dimensional vector space yields $2^n$ basis blades. The highest grade blade $I=e_1\dots e_n$ is also known as the pseudo scalar. $k$-vectors are linear combinations of $k$-blades. In general, the elements of the Clifford algebra are called multi-vectors. We can write them as sums of $k$-vectors $x = [x]_0 + [x]_1 + \dots + [x]_n$, where $[x]_k$ denotes the $k$-vector part of $x$. The geometric product bilinearly extends from blades to multi-vectors. Let us have a look at the product of two $1$-vectors in the Clifford algebra $CL_{2,0,0}(\mathbb{R})$ as an example: \begin{align*} (a_1e_1 + a_2e_2 )(b_1e_1 + b_2e_2) \\ = (a_1b_1 + a_2b_2) + (a_1b_2 - a_2b_1)e_1e_2 \end{align*} The $0$-vector part of the product is the usual scalar product, while the $2$-vector part is the determinant of the two vectors interpreted as rows of a matrix.
Pin and Spin groups
We are interested in the orthogonal transformations of the underlying vector space for a given Clifford algebra. By the Cartan-Dieudonné theorem, every orthogonal transformation can be written as a composition of at most $n$ reflections. The $\textrm{Pin}(p,q,r)$ group is the group generated by the representations of reflections in the Clifford algebra $CL_{p,q,r}(\mathbb{R})$. More precisely, a reflection can be represented by a unit normal vector $a$ of the defining hyperplane, that is: If $P$ is the set of all points satisfying $\sum_{i=1}^n a_ix_i = 0$, then we represent $P$ by the $1$-vector $\sum_{i=1}^na_1e_i$. Note that every unit $1$-vector $p$ represents a plane and that a plane is always represented by two unit $1$-vectors, $p$ and $-p$, which makes $\textrm{Pin}(p,q,r)$ a double cover of the group of orthogonal transformations. Applying a reflection to the a hyperplane can be expressed by a sandwich product: For $1$-vectors $p$ and $q$ we have $p[q]: q\mapsto -pqp^{-1}$ yields a representation of the reflection of the plane $q$ through the plane $p$. Applying multiple reflections to a plane is rather straight forward:
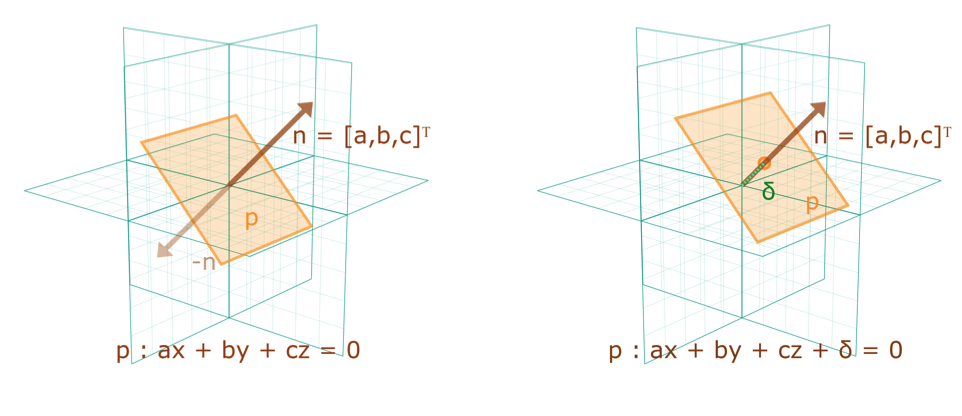 Left, a plane through the origin identified by a normal vector $n = (a b c)^T$ , or equivalently a linear equation $p :
ax+by+cz=0$ .Right,a general plane represented by a unit normal vector $n$ and distance $\delta$, or equivalently by the linear equation $p:ax+by+cz+\delta=0$.
\begin{align*}
p_1[\ldots p_n[q]] &= -p_1-(p_2\ldots-(p_nqp_n^{-1})\ldots p_2^{-1})p_1^{-1} \\
&= (-1)^{n}p_1p_2\ldots p_nqp_n^{-1}\ldots p_2^{-1}p_1^{-1} \\
&= (-1)^{n}(p_1p_2\ldots p_n)q(p_1p_2\ldots p_n)^{-1}
\end{align*}
Hence, the product of the $1$-vectors representing the planes is a representation the of composition of the corresponding reflections. In general, applying a $k$-reflection $u$ to an $\ell$-reflection $v$ yields $u[v] = (-1)^{k\ell}uvu^{-1}$. Note that an uneven number of reflections changes the chirality of the space, which is often an unwanted property. The $\textrm{Spin}(p,q,r)$ group is the even subgroup of $\textrm{Pin}(p,q,r)$, i.e. the subgroup of transformations that preserve the chirality. Note that application of the defined transformation is in fact a group action of $\textrm{Spin}(p,q,r)$ on $\textrm{Pin}(p,q,r)$ since it reduces to conjugation in this case.
Left, a plane through the origin identified by a normal vector $n = (a b c)^T$ , or equivalently a linear equation $p :
ax+by+cz=0$ .Right,a general plane represented by a unit normal vector $n$ and distance $\delta$, or equivalently by the linear equation $p:ax+by+cz+\delta=0$.
\begin{align*}
p_1[\ldots p_n[q]] &= -p_1-(p_2\ldots-(p_nqp_n^{-1})\ldots p_2^{-1})p_1^{-1} \\
&= (-1)^{n}p_1p_2\ldots p_nqp_n^{-1}\ldots p_2^{-1}p_1^{-1} \\
&= (-1)^{n}(p_1p_2\ldots p_n)q(p_1p_2\ldots p_n)^{-1}
\end{align*}
Hence, the product of the $1$-vectors representing the planes is a representation the of composition of the corresponding reflections. In general, applying a $k$-reflection $u$ to an $\ell$-reflection $v$ yields $u[v] = (-1)^{k\ell}uvu^{-1}$. Note that an uneven number of reflections changes the chirality of the space, which is often an unwanted property. The $\textrm{Spin}(p,q,r)$ group is the even subgroup of $\textrm{Pin}(p,q,r)$, i.e. the subgroup of transformations that preserve the chirality. Note that application of the defined transformation is in fact a group action of $\textrm{Spin}(p,q,r)$ on $\textrm{Pin}(p,q,r)$ since it reduces to conjugation in this case.
Projective geometric algebra
All elements of the Euclidean group can be represented as compositions of reflections in planes. The orange k-blades are compositions of orthogonal planes, and represent simultaneously the points, lines, planes as well as the reflections in these elements. In green: compositions of reflections in arbitrary planes make up all isometric transformations
We can use elements of the $\textrm{Pin}(p, q, r)$ group also to act on data by identifying a transformation with its invariant subspace. Hence, a reflection represents a hyperplane, a rotation a line and a roto-reflection a point.
Geometric Clifford algebra networks (GCANs)
The authors define a general parametric group action layer, which allows to integrate the advantages of Clifford algebras into neural network computation. Let $G$ be a group, $X$ a vector space, $\alpha: G \times X\to X$ a group action, and $c$ a number of input channels. A group action layer computes a function $T_{g, w}:= \sum_{i=1}^c w_i \alpha(g_i, x_i)$, where $g_i\in G$.
Group action layers are used in Clifford algebra networks by choosing $G$ to be the $\textrm{Spin}(p,q,r)$ group, $X$ to be the Clifford algebra $CL_{p,q,r}(\mathbb{R})$ and $\alpha$ to be the group action of $\textrm{Spin}(p,q,r)$ on $\textrm{Pin}(p,q,r)$ given by conjugation (application of the defined transformation, as explained above). The group elements are represented by multi-vectors, where the coefficients of the basis blades act as parameters. An uninitialized group element is a template for a geometric transformation that can be refined via gradient decent. Indeed, conjugating with an element of $\textrm{Spin}(p,q,r)$ does not change the type of the represented subspace, but only its position and orientation. Hence, the group action layer can be used to represent a transformation of the input data.
Non-linearities and normalization
The authors propose the use of a particular variant of the multivector Sigmoid Linear Unit, which scales each $k$-vector individually: $x \mapsto \sum_i^n \textrm{MSiLU}_k(x)$, where $\textrm{MSiLU}_k(x) := \sigma(f_k(x)) \cdot [x]_k$. The function $f_k$ is chosen as a learnable linear combination of the basis blade coefficients of $x$. The authors further propose to normalize the output of the group action layer $k$-vector wise by the empirical average over the input channels, i.e. $[x]_k \mapsto s_k\frac{[x]_k - \mathbb{E}[[x]_k]}{||\mathbb{E}[[x]_k]||}$.
The proposed nonlinearity and normalization are designed to maintain the type of the represented subspace, i.e. the type of the input data. Hence, the entire networks can be designed to preserve the type of the input data. This is a significant advantage over the previous approach by the authors [Bra23C] that used the geometric product as basis for a layer that computes within a Clifford algebra. However, the Rotational Clifford Networks that were also defined in the paper above, turn out to be close to be a special case of GCANs.
Modeling dynamical systems
GCANs are evaluated on multiple dynamical system modeling tasks and show that they are able to improve upon the state of the art in all cases. The first experiments shows how the properties of higher dimensional Clifford algebras can be used to model complex object trajectories. The second and third experiments show that GCANs are able to outperform classical approaches in modeling large-scale fluid mechanics problems.
Tetris
Test MSE results of the Tetris experiment as a function of the number of training trajectories. Left: comparison of different MLP models, center: comparison of different GNN models, right: comparison of the best MLP and GNN models when velocities are included.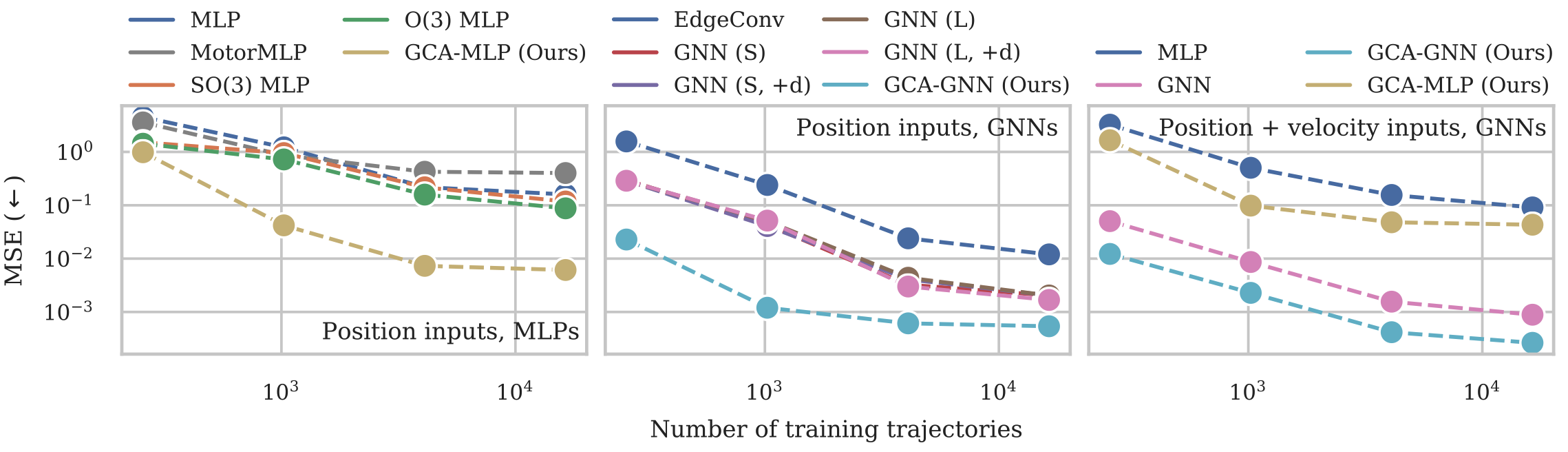
Shallow Water Equations
MSE results of the large-scale fluid mechanics experiments as a function of the number of training trajectories. The authors compare ResNet (left) and UNet (center) models on the shallow water equations. Right: UNet comparison on the Navier-Stokes equations.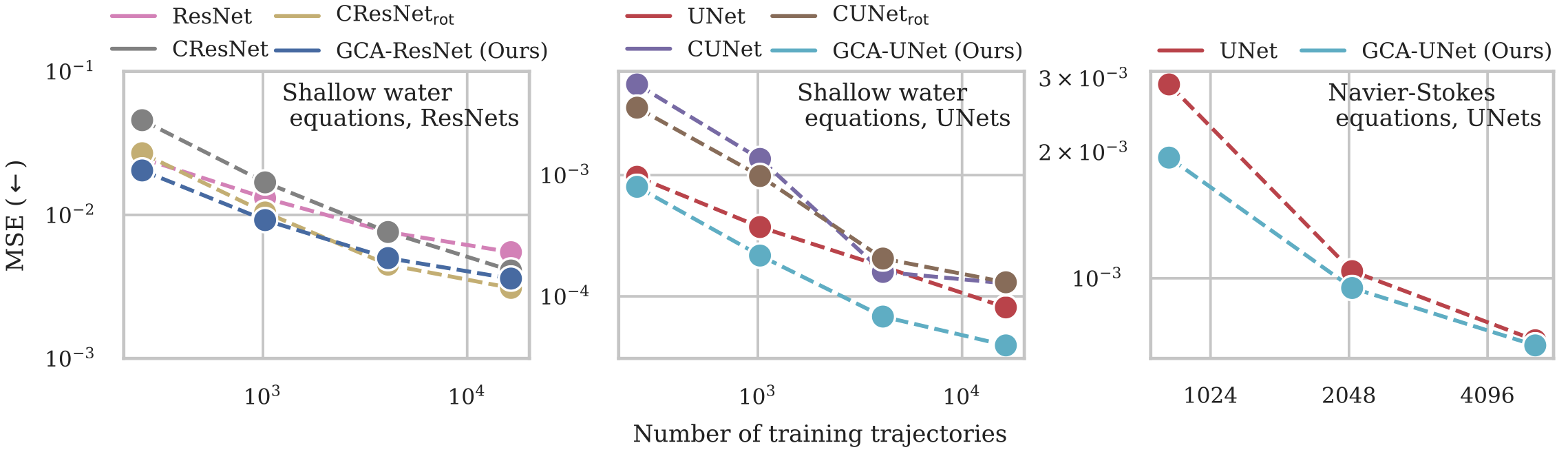
Incompressible Navier-Stokes Equations
 Example input, target, and predicted fields for the shallow water equations. Predictions are obtained by the GCA-UNet model when using 16384 training trajectories.
Finally, they conduct a Navier-Stokes large-scale PDE experiment with a scalar (smoke density) field and a velocity field. The scalar smoke field is advected by the vector field, i.e. as the vector field changes, the scalar quantity is transported with it. The authors use essentially the same setup as for the shallow water equations, i.e. use $CL_{3,0,0}(\mathbb{R})$ to represent the velocity field and the scalar field. The authors compare against a UNet baseline. Although the improvement is not as significant as in the shallow water equations, the authors show that the Clifford network is able to outperform the baseline, especially in low data regimes.
Example input, target, and predicted fields for the shallow water equations. Predictions are obtained by the GCA-UNet model when using 16384 training trajectories.
Finally, they conduct a Navier-Stokes large-scale PDE experiment with a scalar (smoke density) field and a velocity field. The scalar smoke field is advected by the vector field, i.e. as the vector field changes, the scalar quantity is transported with it. The authors use essentially the same setup as for the shallow water equations, i.e. use $CL_{3,0,0}(\mathbb{R})$ to represent the velocity field and the scalar field. The authors compare against a UNet baseline. Although the improvement is not as significant as in the shallow water equations, the authors show that the Clifford network is able to outperform the baseline, especially in low data regimes.
Conclusion
I think the paper is a very interesting contribution to the field of geometric deep learning. The authors show that Clifford algebras are a very natural choice to represent geometric transformations and that they can be used to improve upon the state of the art in modeling dynamical systems. With their Geometric Clifford Algebra Networks, the authors unlock the potential of Clifford algebras for deep learning applications. Conjugation proves to be the more natural basis for a deep learning layer, allowing a consistent transformation objects by design. The possibility to restrict the group actions to certain types of transformations through the geometric template effectively yields a new kind of geometric prior complementing the established symmetry and scale separation principles. One should point out, however, that the presented experiments compare against generic baselines don’t employ other specialized techniques for neural PDE solving. It would be very interesting to see if we can beneficially combine Geometric Clifford Algebra Networks with techniques like operator learning. I am looking forward to see more work in this direction.
