The difficulty to understand the decisions of complex neural networks is a major limiting factor for their adoption in practice. While a huge amount of techniques have been proposed, many of them provide rather technical explanations which are not easily understood by laymen.
A good example are saliency
maps.
In audio prediction tasks one typically highlights the saliency maps on
audiograms or spectrograms. However, such saliency maps offer only limited
transparency because spectrograms are too technical to be interpreted by
non-domain experts. Another drawback is that the most important regions for a
decision might coincide among all possible classes. For instance, the saliency
maps
for an emotion prediction model trained on face images might always highlight
the eyes and the mouth of the face. Hence, saliency maps are insufficient to
assess why a certain emotion was predicted by the model. The authors of
[Zha22R] (best-paper award at
CHI 2022) argue further that
the way in which an AI system makes its decision should be human-like
in order to earn people’s trust. They draw inspiration from theories
in cognitive psychology by designing their architecture after the perceptual
process [Car78P], which states that people
select, organize, and interpret information to make decisions: 1) First, a
subset of the sensory information is selected. 2) The selected regions get
organized into meaningful cues, e.g. ears, mouth, and nose for a face. 3)
Finally, the low-level cues get interpreted towards high-level concepts, e.g.
the characteristics of ears, mouth, and nose are used to distinguish humans from
animals.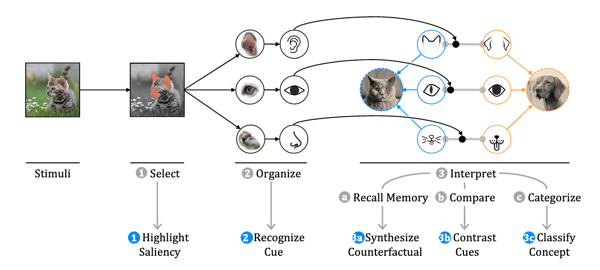
In the proposed architecture, the first step of the perceptual process relates
to saliency maps where the high saliency regions represent the selected subset
of the sensory information. The cues are domain specific and predefined.
Depending on the context they can either be computed directly from the input or
learned from annotated examples. Most theories assume that the brain generates
or remembers counterfactual examples and compares the current perception against
them on the cues in order to attribute the perception to the high level
concepts. The authors propose to use generative adversarial networks and style
transfer to generate examples from all classes that are otherwise similar to the
input. The system uses the differences on the cues to provide contrastive cues
as an additional layer of explanation. The final classification is made from an
embedding of the input that is obtained from the original model and the
contrastive cues, which makes the decision process more relatable. The entire
architecture is depicted below. The system provides the saliency maps, the cues
and the contrastive cues to explain the decision.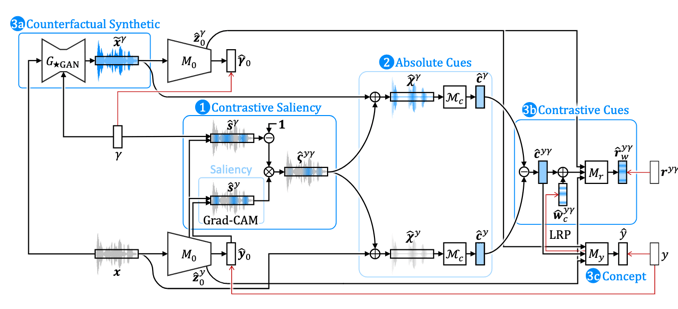
The paper concludes with extensive empirical studies on a voice emotion prediction task. They show that the model does not only provide better explanations in think-alout and controlled user studies, it also outperforms the vanilla convolutional neural network model in accuracy. If you would like to try it, there is a nice demo and some short video presentations on the authors lab page.
