ReLU networks are special in the sense that they are much easier to analyze than networks with other types of non-linear activations. They represent piecewise linear functions that can be partitioned into affine functions over polyhedral regions in the input space (tessellation). The regions are often called linear regions in the literature. The transition from one region into another changes the slope of the input-output function as well as the activation pattern of the network neurons. The theoretical study of these networks greatly helped improving our understanding of deep learning systems.
Previous research has focused on providing upper bounds for the number of linear regions as a function of the number of neurons and layers as a measure of the networks expressive power [Mon14N]. Betti numbers have been used for measuring the complexity of a neural network’s decision surface from a topological point of view [Bia14C].
The paper [Mos22T] starts by taking a critical look at both practices. Inspired by fractal geometry the authors construct simple examples with vanishing Betti numbers (i.e. without holes) but with a highly non-convex decision surface. The second example, to check that all components of an n-dimensional input are strictly positive, shows that a decision surface that can be described in terms of an intersection of n half-spaces can generate exponentially many linear regions when realized with a Relu network.
The authors propose to use the notch number as an additional parameter for measuring the complexity of the decision surface of a neural network. The notch number counts the non-convex “extensions and recesses” in the decision surface. Similar to Betti numbers it is invariant under different Relu networks that realize the same function. It gives a more consistent measure of complexity of the represented function than the number of linear regions. Indeed, the number of linear regions depends on the activation patterns of the network’s neurons, which tends to create more linear regions as the number of neurons or depth grows. This shows that the number of linear regions is not necessarily a good measure of the complexity of the decision surface.
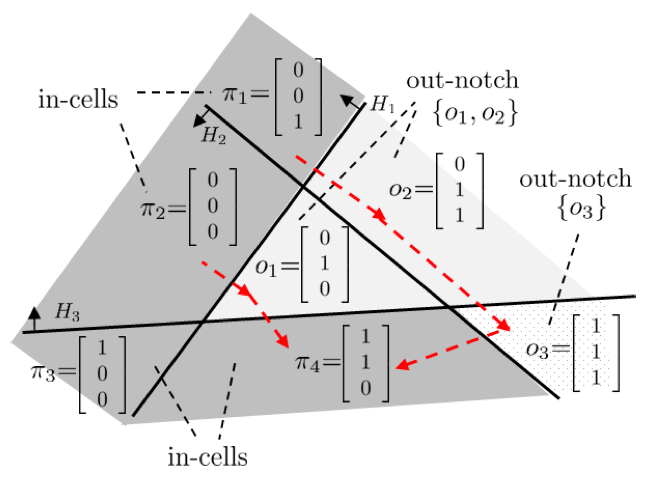
As computing the tessellation that is induced by a deep network is practically impossible, the authors take a deeper look into the compositional structure of neural networks.
They introduce the class of tessellation-filtering networks as networks with the following property: If a tessellation filtering network is used as the final layers of a neural network, it can only coarsen the tessellation that is induced by the body network. These tessellation-filtering networks are highly related to Boolean algebra which makes them easy to handle mathematically.
Building upon that, a local representation theorem in terms of tessellation-filtering networks in the neighborhood of a given point (in activation space) can be derived. This can be seen as a generalization of the polyhedra that are obtained from fixing the entire activation space to a setting where we fix only the activation pattern of the body network. Since tessellation-filtering networks are mathematically well manageable, this allows a more fine-grained analysis of the decision surface. This yields a framework to decompose a network along a specific layer into a tessellation and a shape complexity part which is represented by the tessellation-filtering neural network. At the moment, further research is needed to analyze the capability of this method in more detail since it is not clear to which extent this technique will be applicable in practice. Nevertheless, I think that the local representation theorem by itself sheds more light on the reasons behind the representational power of ReLu networks.
