In our series on diffusion models we have analysed the mathematical details of de-noising diffusion probabilistic models (DDPM) for generative tasks. The recent release of powerful text-to-image models (such as DALLE-2, midjourney or stable diffusion), which create highly diverse images that follow given text prompts, has sparked a lot of media attention but has also highlighted several limitations. For example, finding the right prompt or changing small details of an already created image has proved to be very tedious since even small modifications of the input lead to completely different outcomes.
The recent paper [Her22P] introduces a way to fine-tune generated images only through textual input. Given two prompts P= “lemon cake” and P’=”monster cake”, the paper shows that acting directly on the attention maps of the model with input P’ and switching them with those of P smoothly transitions a simple lemon cake to a more “monstrous” one, keeping the original high level features (Figure 1).

Figure 1. Difference between the images generated with the full prompt (lower part of the image) with those that fix the attention maps to “lemon cake” but change the prompt (upper part of the image) .
The paper explores different ways to modify the textual prompt to accentuate different features. Apart for the already mentioned switching of one word for another, they also investigate adding/removing words or up/down weighing their importance. Figure 2 shows a scheme of how this is done in practice. In Figure 3 you can also find a couple of examples of the up-weighting of features.
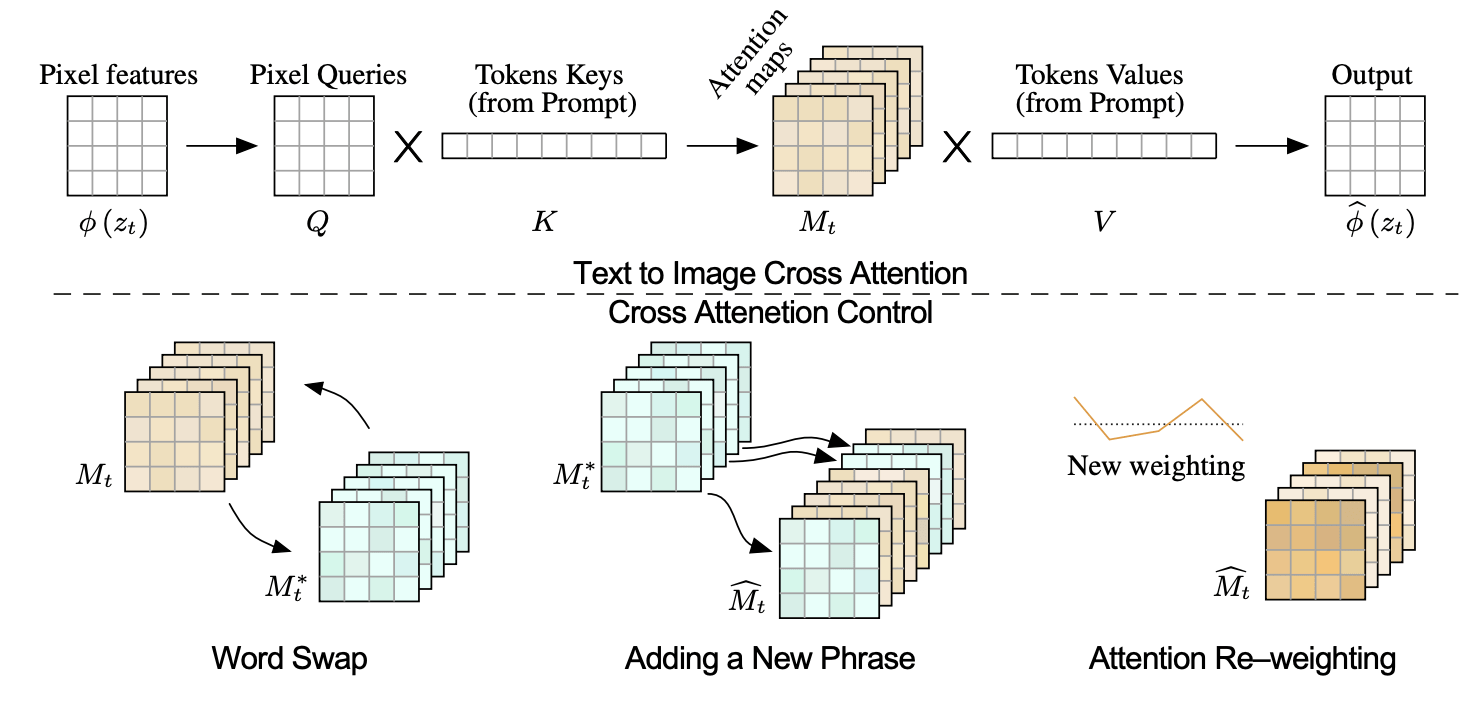
Figure 2. Given the (noisy) image at time $t$, indicated as $z_t$, $\phi(z_t)$ represents the output of a generic layer of the neural network. From $\phi(z_t)$ one calculates Query, Key and Value matrices, which are then, through multi-head attention, used to calculate the output of the layer. In this paper, attention maps are directly modified as shown in the lower part of the image, by swapping, adding or re-weighting single maps.

Figure 3. From left to right, “snowy” and “fluffy” are progressively made more important in the attention maps, and the model reacts accordingly.
What I find most interesting about this approach is that through simple manipulations of the attention maps and with no further training we can control the end result of the inference in an intuitive way. This draws interesting connections with explainability (e.g. with counterfactual and contrastive explanations) and with the interpretation of the various elements that constitute the attention mechanism (namely Key, Query and Value).
