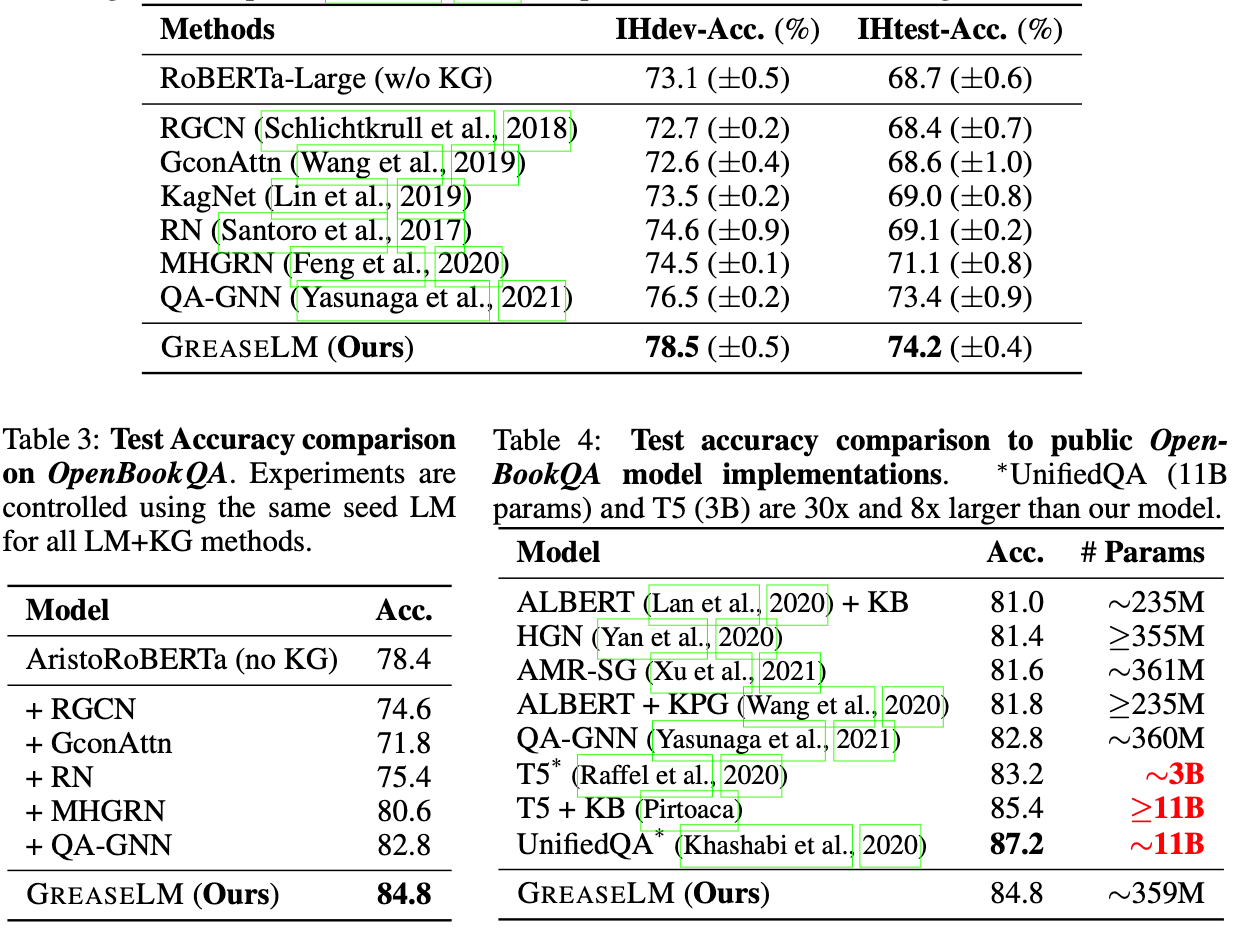
Large pre-trained language models have become the de facto standard for question answering tasks. These models implicitly store broad knowledge about the world during training on large text corpora and can provide high accuracy answers when fine-tuned to a specific task. However, they struggle if the questions are from a different distribution than the training examples. Often one observes that these model rely on simple (sometimes even spurious) patterns to offer shortcuts to the answer (cf. here).
Massive knowledge graphs such as ConceptNet, Wiki-data, Yago, or Freebase offer a principled way to infer answers from the external knowledge that is explicitly encoded as triplets. However, they are hard to apply if one cannot easily translate the question into a logical query, as it is the case if the question are given i natural language.
The paper [Zha22G] tries to combine both worlds to improve the quality of question answering systems. They fine-tune a pre-trained language model that processes the question and pre-trained graph neural network that processes the knowledge graph which are both run in parallel. This is not the first incarnation of the idea, but it differs in the way the two systems interact. While previous approaches allowed only limited interaction between the two systems, e.g. by combining both output representations in the end, the new approach allows the two systems to interact after each layer. This is done via an additional interaction token as input for the language model and an additional interaction node as input for the knowledge graph. After each layer, the representations of the interaction token and node are put together into a mixer module that computes the interaction inputs for the next layer.
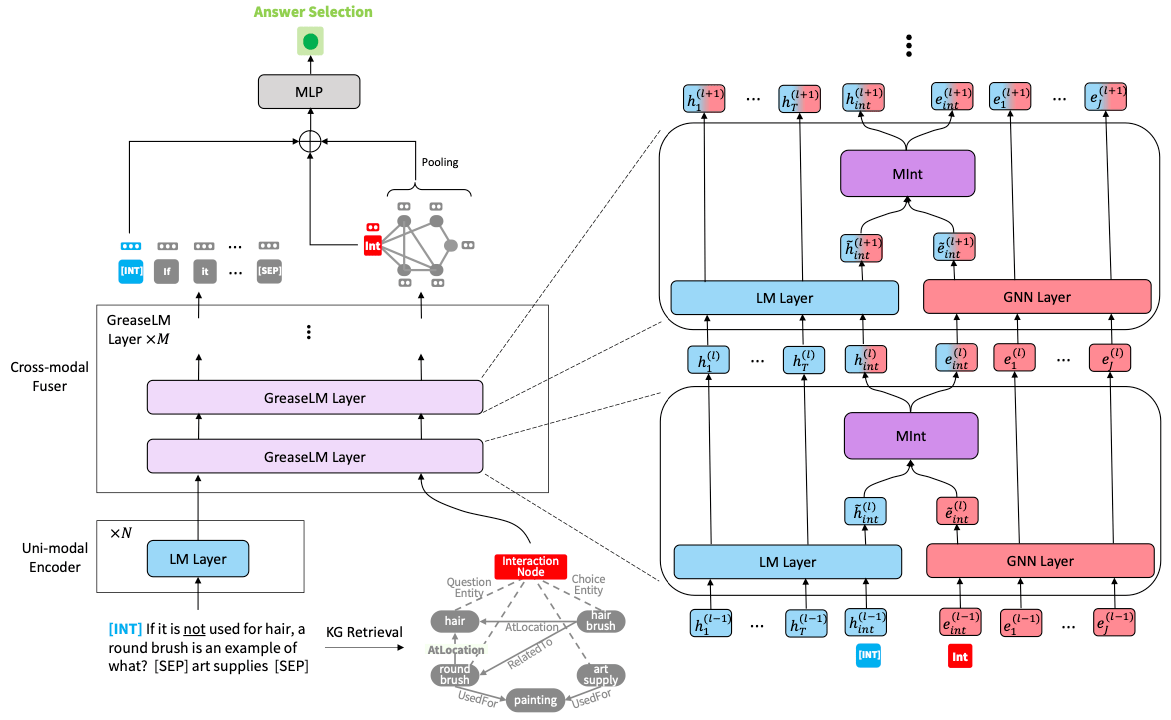
The idea is independent of architectures and can be used with any pre-trained language model and graph neural network. In fact, the authors conduct extensive experiments with several SOTA language models to validate that their method consistently improves the performance wrt. vanilla fine-tuned language models. Additionally, they find that their approach is even able to outperform strong models that have up to 8x more parameters.