Pre-trained language models (PLM) that are used for sentence encoding, like BERT and variations thereof, are an important element of nearly every NLP practitioner’s toolbox. However, these models are trained on general purpose corpora and might struggle in applications requiring specific knowledge. The paper introducing DictBERT [Yu22D] at this year’s IJCAI provides a simple and principled way for integrating external knowledge bases (in the form of dictionaries) with sentence encoders.
The principle of DictBERT is straightforward. Given a dictionary that maps
entries to descriptions, as well as a thesaurus with synonyms and
antonyms, one fine-tunes a sentence encoder on two tasks in separate training
steps:  Table 4: Experimental results on CommonsenseQA (CSQA) and OpenBookQA (OBQA)
prediction of entries from descriptions, and minimisation of a
contrastive loss between synonyms and antonyms. On the latter task, each entry
is concatenated with its description to create inputs for the contrastive loss.
Table 4: Experimental results on CommonsenseQA (CSQA) and OpenBookQA (OBQA)
prediction of entries from descriptions, and minimisation of a
contrastive loss between synonyms and antonyms. On the latter task, each entry
is concatenated with its description to create inputs for the contrastive loss.
During inference, DictBERT is used as a plugin. Given a sequence that needs to be encoded, one first computes the original encoding from a normal BERT. Then, in parallel, one extracts selected entries from the input sentence, uses the dictionary to find descriptions for them, and encodes these descriptions with DictBERT. The authors have proposed several strategies for combining these entry encodings with the original encoding, resulting in higher quality representations (measured by performance on downstream tasks) compared to the bare encoder or other strategies of incorporating external knowledge, see the tables below. As the dictionary is finite, DictBERT is actually not needed at inference time, since one could simply store encodings of all descriptions in the dictionary and thus obtain a direct mapping from entry to encoding. All that is left at inference is then to combine encodings of selected entries with the original encodings (see comment on this below).
While not explicitly mentioned by the authors, this or similar techniques might be particularly useful for applying BERT-like models to sentences with specific jargon, since the mapping of entries to descriptions effectively replaces the jargon by common language, on which the general-purpose encoders were originally trained. A model checkpoint is available on huggingface and open source code for fine-tuning can be found on GitHub.
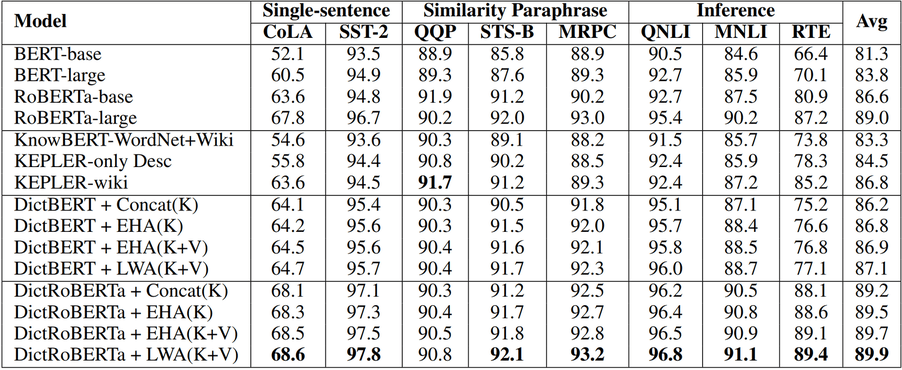 Table 5: Experimental results on the GLUE development set. The parameter of
DictBERT is based on BERT-large. For parameter initialization, KnowBERT uses the
BERT-base, while KEPLER uses RoBERTa-base.
Table 5: Experimental results on the GLUE development set. The parameter of
DictBERT is based on BERT-large. For parameter initialization, KnowBERT uses the
BERT-base, while KEPLER uses RoBERTa-base.In my opinion the paper, while a nice first experiment and introduction to using knowledge bases for representations, is a bit simplistic. Synonyms and antonyms are not opposites linguistically, so the benefits of using antonyms instead of random sentences or some hard negative mining strategy for contrastive tasks are unclear. There were no ablation studies on removing this task or on using random descriptions as negative samples. The selection of which entries to encode during inference is also not explained, but it clearly cannot be all the words in a sentence.
Using the descriptions alone, without any DictBERT, should already give improvements by injection of additional knowledge. One could obtain encodings of these descriptions with the original BERT or enlarge the input sentences by replacing entries by pieces of descriptions. Also, the strategies for combining entry encodings with the original encoding seem rather ad hoc and simplistic, there might be room for improvement there. Overall, I am not convinced that DictBERT is the best way of using a dictionary for improving representation quality, although it is an interesting step in this direction.
