Mathematical optimization (convex and non-convex) is a large and mature field of research, as is policy optimization in reinforcement learning. A fusion of ideas from the two fields gives rise to improvements upon naive gradient descent as used in policy gradient algorithms like REINFORCE. The improvements considered in the present text boil down to optimizing a regularized or constrained objective function rather than just the discounted expected sum of rewards. While trust-region policy optimization (TRPO) essentially uses natural gradients and restricts the step size to enforce proximity constraints on policy updates, the significantly simpler proximal policy optimization (PPO) introduces constraints that modify the original objective in a more RL-specific fashion. The actual practical algorithms are motivated by rigorous analysis but involve several approximations and simplifications. Experimental results of TRPO and PPO display much more stability and reliability than their non-regularized counterparts and thereby show that many desired properties are not lost in the approximations. PPO is a state-of-the-art algorithm which is implemented in most major RL frameworks, like rllib, stable-baselines and others.
1 Introduction to Trust Region methods
Before we dive into the main results of the papers, let us briefly describe trust region methods and other general methods for numerical optimization.1 1 For a self-contained introduction, we recommend [Noc06N]. As we will see, several main results and improvements in the TRPO and PPO papers are very natural and follow standard approaches from the point of view of optimization.
In this section we will be concerned with minimizing a twice differentiable function $f :\mathbb{R}^N \rightarrow \mathbb{R}$. First notice that several optimization algorithms can be understood as the successive application of the following steps:
Algorithm 1: Approximation Based Optimization
Select some $x_{0}$ as starting point. At each iteration $k$:
Find a local approximation to $f$ close to the current point $x_{k}$ that can be minimized (over the entire domain of definition $\mathcal{D}_{x}$) with less effort than $f$ itself. Such approximations are often called models, and we will denote them by $m_{k}$. Find a minimum of the model.2 2 Note how here we allow for $m_{k}$ without unique minima, as is the case in applications in RL. However, in many applications $m_{k}$ will be convex and $\operatorname{argmin}m_{k}$ will be a single point. For gradient based optimization methods this distinction is usually of little practical importance - one uses the point where gradient descent has converged.
\[ x_{\min} \approx x^{\ast} \in \operatorname{argmin}_{x \in \mathcal{D}_{x}} (m_{k} (x)) . \]
Set $x_{k + 1} \leftarrow x_{\min}$ and repeat.
For example, the following quadratic approximation to $f$:
\begin{eqnarray*} m^{\operatorname{grad}}_{k} (x) & := & f (x_{k}) + (x - x_{k})^{\top} \cdot \nabla f (x_{k}) \\\ & & \quad + \frac{1}{2 t_{k}} | x - x_{k} |^2 \end{eqnarray*}
yields the update rule of gradient descent with step size $t_{k}$:
\[ x_{k + 1} = x_{k} - t_{k} \nabla f (x_{k}) . \]
For small enough $t_{k}$ and $f$ with Lipshitz continuous gradients, the above model actually forms a majorant of $f$ (many proofs of convergence of gradient descent are based on this). However, the above approximation is clearly very crude and does not take into account the curvature of $f$. Constructing the model with the second order expansion of $f$ results in Newton’s Method. With the model
\begin{eqnarray*} m^{\operatorname{Nwt}}_{k} (x) & := & f (x_{k}) + (x - x_{k})^{\top} \cdot \nabla f (x_{k}) \\\ & & \quad + \frac{1}{2} (x - x_{k})^{\top} H_{k} (x - x_{k}), \label{newton-model}\tag{1} \end{eqnarray*}
where $H_{k}$ is the Hessian of $f$ at $x_{k}$, we obtain the update rule:
\[ x_{k + 1} = x_{k} - H^{- 1}_{k} \nabla f (x_{k}) . \]
The strategy outlined above clearly has a flaw: the models will almost always be poor approximations to $f$ far from $x_{k}$ - something that we have not taken into account. This situation can be improved by restricting the parameter region where we trust our model prior to optimization - hence the name trust region.
Usually, we cannot judge a priori whether the model is sufficiently good within the selected region (if it is not, then the region was too large) or whether on the contrary the region can be extended to allow for larger step sizes. A posteriori, however, we can compare the actual improvement in the objective, $\Delta f$ to the improvement in the model $\Delta m$ (the predicted improvement) . If the ratio $\Delta f / \Delta m$ is too small, we should reject the step and shrink the trust region. If the ratio is too large, we should increase it. To summarize, the improved algorithm works as follows [Con00T]:
Algorithm 2: Trust Region Optimization
Select some $x_{0}$ as starting point. At each iteration $k$:
Choose an approximation of $f$ around $x_{k}$, call it $m_{k} :\mathbb{R}^N \rightarrow \mathbb{R}$.
Choose a trust region $U_{k}$ that contains $x_{k}$. Usually
\[ U_{k} := \lbrace x : | x - x_{k} |_{k} \leqslant \Delta _{k} \rbrace, \]
for some norm $| \cdot |_{k}$ and radius $\Delta _{k} > 0$.
Find an approximation of a minimum of $m_{k}$ within the trust region
\[ x_{\min} \approx x^{\ast} \in \operatorname{argmin}_{x \in U_{k} } m_{k} (x) . \]
Compute the ratio of actual-to-predicted improvement:
\[ \rho _{k} := \frac{f (x_{k}) - f (x_{\min})}{m_{k} (x_{k}) - m_{k} (x_{\min})} . \]
If $\rho _{k}$ is sufficiently large, accept $x_{\min}$ as the next point (i.e. $x_{k + 1} \leftarrow x_{\min}$), otherwise don’t move ($x_{k + 1} \leftarrow x_{k}$)
If $\rho _{k}$ is sufficiently large, increase the next trust region, if it is too small then shrink it. With $U_{k}$ as above, this step usually amounts to scaling the radius, i.e. $\Delta _{k + 1} = \varepsilon _{k} \Delta _{k}$ with the scaling factor $\varepsilon _{k}$ depending on $\rho _{k}$.
Increment $k$ by $1$ and go to step 1.
![]() Figure 1. Trust Region
Optimization. Four steps of a trust region algorithm with a quadratic
model; from left to right, top to bottom. The true objective is not shown.
In the first step $\rho _{0}$ is sufficiently large, so $x_{\min}$ is
accepted and the trust region increased. Same for the second step. In the
third step the trust region is too large, the model is not a good
approximation of the objective and as consequence $\rho _{2}$ is not large
enough. Therefore, the update of $x_{2}$ is rejected and instead the trust
region is decreased, giving a different $x_{\min}$, which now can be
accepted. Images taken from [Con00T].
Figure 1. Trust Region
Optimization. Four steps of a trust region algorithm with a quadratic
model; from left to right, top to bottom. The true objective is not shown.
In the first step $\rho _{0}$ is sufficiently large, so $x_{\min}$ is
accepted and the trust region increased. Same for the second step. In the
third step the trust region is too large, the model is not a good
approximation of the objective and as consequence $\rho _{2}$ is not large
enough. Therefore, the update of $x_{2}$ is rejected and instead the trust
region is decreased, giving a different $x_{\min}$, which now can be
accepted. Images taken from [Con00T].
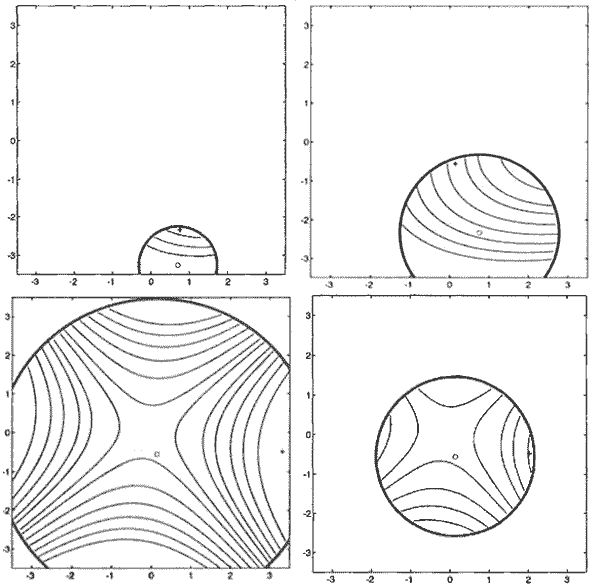
Figure 1 illustrates this scheme with the contour lines of a quadratic approximation of the true objective shown at several steps.
2 Update rules from trust region methods
Let us ignore steps 4 and 5 from the above algorithm for a moment and analyze what kind of update rules we obtain from different trust region constraints. With a linear model
\begin{equation} m^{\operatorname{linear}}_{x_{k}} (x) = f (x_{k}) + (x - x_{k})^{\top} \cdot \nabla f (x_{k}), \label{linear-model}\tag{2} \end{equation}
and a trust region $U_{k} := \left\lbrace x : \frac{1}{2} | x - x_{k} |^2 \leqslant \delta^2 \right\rbrace$ we have the update rule
\[ x_{k + 1} = x_{k} - \delta \frac{\nabla f (x_{k})}{| \nabla f (x_{k}) |} . \]
This update is commonly known as normalized gradient descent.
Using the quadratic approximation (1) as model with the same constraint as above we obtain the rule:
\[ x_{k + 1} = x_{k} - (H_{k} + \lambda)^{- 1} \nabla f (x_{k}), \]
where $\lambda$ is the Lagrange multiplier of the constraint. This update rule is the essence of the widely used Levenberg-Marquardt algorithm [Mar63A].
A Euclidian sphere in the parameter space $\mathbb{R}^N$ typically does not reflect the geometry relevant for the optimization problem. Some problem-specific distance on $\mathbb{R}^N$ might do a better job in specifying what it means for $x$ to be too far away from $x_{k}$. A particularly simple and useful choice is often a suitable symmetric and positive-definite matrix $F (x_{k})$, which could be e.g. a metric tensor induced by some distance function. The trust region constraint then becomes
\begin{equation} \frac{1}{2} (x - x_{k})^{\top} F (x_{k}) (x - x_{k}) \leqslant \delta^2, \label{custom-trust-region}\tag{3} \end{equation}
and the update rule from the linear model (2) takes the form
\begin{equation} x_{k + 1} = x_{k} - D_{k} \nabla f (x_{k}), \label{custom-metric-update}\tag{4} \end{equation}
where
\[ D_{k} := \frac{\delta}{\sqrt{\nabla f^{\top} (x_{k}) F^{- 1} (x_{k}) \nabla f (x_{k})}} F^{- 1} (x_{k}) . \]
An interesting choice for $F$ is the Hessian $H_{k}$ of $f$ at $x_{k}$, which essentially means that distances between $x$ and $x_{k}$ are measured in units of the curvature of $f$ at $x_{k}$. Then the update rule (4) corresponds to a variant of the damped Newton method. As an alternative for the full Hessian, one could use only the diagonal components of $H_{k}$ for setting up the constraint, i.e. $F_{k} := \operatorname{diag} (H_{k})$ (a choice that is supported by heuristics). Then, using a trust region of the form (3) together with the second order model (1) results in Fletcher’s modification of the Levenberg-Marquardt update rule [Fle71M]:
\[ x_{k + 1} = x_{k} - [H_{k} + \lambda \operatorname{diag} (H_{k})]^{- 1} \nabla f (x_{k}) . \]
Using linear or quadratic approximations with different trust region constraints gives rise to many of the standard optimization algorithms that are commonly used in practice. As we will see below, several improvements of the naive policy gradient algorithm in reinforcement learning are based on exactly the same ideas that we highlighted in this section.
3 Notation and the RL objective
In all that follows we will consider an infinite horizon Markov decision process with states $s_{t}$ and actions $a_{t}$. For notational simplicity, we assume that state and action spaces are discrete.3 3 With some effort, the results stated can be transferred to continuous spaces. Here we are in the context of model-free reinforcement learning and we want to find a policy from a family of functions $\lbrace \pi _{\theta} : \theta \in \mathbb{R}^n \rbrace$ differentiable wrt. their parameters. The goal is to find the $\theta$ maximizing the expected sum of discounted rewards
\begin{equation} \eta _{\pi _{\theta}} =\mathbb{E}_{ \pi _{\theta}} \left[ \sum_{t = 0}^{\infty} \gamma^t r (s_{t}, a_{t}) \right] . \label{sum-rewards}\tag{5} \end{equation}
In what follows, we will often omit the subscript $\theta$ when it is clear which policy is meant, or if a statement applies to any policy $\pi$. We write $\pi _{k}$ for $\pi _{\theta _{k}}$.
We assume stochastic transition dynamics and, for notational simplicity, denote by $\tau _{t}$ the conditional distribution of $s_{t + 1} |a_{t}, s_{t}$.4 4 This is not to be confused with the usual notation of $\tau$ for the distribution of trajectories. The value, Q and advantage functions are defined as
\begin{eqnarray*} V_{\pi} (s_{t}) & = & \mathbb{E}_{\pi} \left[ \sum^{\infty}_{k = 0} \gamma^k r (s_{t + k}) \right]\\\ & = & r (s_{t}) + \gamma \mathbb{E}_{a_{t} \sim \pi (s_{t})} [\mathbb{E}_{\tau _{t}} [V_{\pi} (s_{t + 1})]], \end{eqnarray*}
\[ Q_{\pi} (s_{t}, a_{t}) = r (s_{t}) + \gamma \mathbb{E}_{\tau _{t}} [V_{\pi} (s_{t + 1})], \]
and
\[ A_{\pi} (s_{t}, a_{t}) = Q_{\pi} (s_{t}, a_{t}) - V_{\pi} (s_{t}) . \]
From these definitions directly follows:
\begin{equation} \begin{array}{lll} V_{\pi} (s_{t}) & = & \mathbb{E}_{a_{t} \sim \pi (s_{t})} [Q (s_{t}, a_{t})],\\\ 0 & = & \mathbb{E}_{a_{t} \sim \pi (s_{t})} [A_{\pi} (s_{t}, a_{t})], \end{array} \label{RL-identities}\tag{6} \end{equation}
and
\begin{eqnarray*} A_{\pi} (s_{t}, a_{t}) & = & r (s_{t}) + \gamma \mathbb{E}_{\tau _{t}} [V_{\pi} (s_{t + 1})] \label{advantage-function}\tag{7}\\\ & & \quad - V_{\pi} (s_{t}) . \end{eqnarray*}
3.1 Approximating the objective
As explained in Section 1, before we start the optimization at each step $k$ we need a local model around $\theta _{k}$ for the full objective (5).5 5 In the literature referenced, the notation $\theta _{\operatorname{old}}$ is used instead of $\theta _{k}$. We will use the following approximation to $\eta _{\pi}$:
\begin{equation} m_{k} (\theta) := \eta _{\pi _{k}} + \sum_{s} \rho _{\pi _{k}} (s) \mathbb{E}_{a \sim \pi _{k} (s)} \left[ \frac{\pi _{\theta} (a|s)}{\pi _{k} (a|s)} A_{\pi _{k}} (a, s) \right], \label{reward-model}\tag{8} \end{equation}
where
\begin{equation} \rho _{\pi} (s) := \sum_{t = 0}^{\infty} \gamma^t \mathbb{P}_{\pi} (s_{t} = s) \label{state-density}\tag{9} \end{equation}
is the (un-normalized) discounted state density, with $s_{0} \sim \rho
_{0}$ for some initial state distribution $\rho _{0}$.6
6 If there is a discount
factor γ<1, the state density is not a probability distribution
since $\sum_{s} \rho _{\pi} (s) = \frac{1}{1 - \gamma} .$ If no discount
factor is used, $\rho _{\pi}$ usually denotes the stationary distribution of
states after following $\pi$ for a long time, which is assumed to exist. I.e.
$\rho _{\pi} (s) :=$$\underset{T \rightarrow \infty}{\lim} \frac{1}{T}
\sum^T_{t = 0} \mathbb{P}_{\pi} (s_{t} = s) .$ This is a proper probability
distribution. In the RL literature one can often find expressions of the type
$\mathbb{E}_{\rho _{\pi} (s)} [f (s)]$, which should be interpreted as
$\sum_{s} \rho _{\pi} (s) f (s)$, even when a discount factor is present and
$\rho _{\pi}$ is not properly normalized. Due to the
vanishing expectation of the advantage function (6), we
immediately see that
\[ m_{k} (\theta _{k}) = \eta _{\pi _{k}} . \]
Moreover:
\[ \nabla m_{k} (\theta _{k}) =\mathbb{E}_{\pi _{\theta }} [\nabla \log \pi _{\theta _{k}} (a|s) Q_{\pi _{k}} (a, s)], \]
which is a well-known expression for the policy gradient [Sut99P]. Therefore, (8) is a first order approximation to $\eta _{\pi _{\theta}}$ around $\theta _{k}$.
With a slight abuse of notation, in modern literature (including the PPO paper [Sch17P]) equation (8) is usually written as
\[ m_{k} (\theta) := \eta _{\pi _{k}} +\mathbb{E}_{\pi _{k}} \left[ \frac{\pi _{\theta} (a|s)}{\pi _{k} (a|s)} A_{\pi _{k}} (a, s) \right] . \]
4 Natural gradients, TRPO and PPO
With the very basic definitions that we have set up above, we can already make a lightning summary of the results of three important papers in RL. All one has to do is to combine ideas from trust region optimization with the objective/model (8).
Since policies are probability distributions, a natural notion of distance for them is given by the KL-divergence.7 7 One reason for the “naturality” of KL-divergence for constraints is its information-theoretic interpretation. Note that it also forms an upper bound of the total variation divergence $\delta$ through Pinsker’s inequality $\delta (P, Q) \leq \sqrt{1 / 2 D_{\operatorname{KL}} (P|Q)}$, where $P, Q$ are arbitrary probability distributions. However, arguably the main reason that makes it natural is that its second derivative (for distributions from a parametrized function family), the Fisher information matrix that we use below to formulate trust-region constraints, gives a metric tensor on the corresponding space of probability distributions. This means that distances between policies measured according to the Fisher information are parametrization invariant. This line of thought was used in the paper that originally introduced natural gradients for RL [Kak01N]. Even though it is not symmetric and therefore cannot really be understood as a proper distance, its second order approximation is the positive definite Fisher information matrix which can be used as a metric tensor for constructing the constraint
\[ \begin{array}{l} D_{\operatorname{KL}} (\pi _{k} (\cdot |s), \pi _{\theta} (\cdot |s)) \approx\\\ \hspace{5em} \frac{1}{2} (\theta - \theta _{k})^{\top} F (\theta _{k}, s) (\theta - \theta _{k}), \end{array} \]
with
\[ F (\theta _{k}, s)_{i, j} = \frac{\partial^2}{\partial \theta _{i} \partial \theta _{j}} D_{\operatorname{KL}} (\pi _{k} (\cdot |s), \pi _{\theta} (\cdot |s)) . \]
Thus, a natural bound for $\pi _{\theta}$ not being too far from $\pi _{k}$ is to demand that on average the second order approximation of the KL-divergence of $\pi _{\theta}$ and $\pi _{k}$ is smaller than some radius $\delta$, resulting in the trust region constraint
\begin{equation} \frac{1}{2} (\theta - \theta _{k})^{\top} \mathbb{E}_{\pi _{k}} [F (\theta _{k}, s)] (\theta - \theta _{k}) \leqslant \delta . \label{trpo-constraint}\tag{10} \end{equation}
This is a constraint of the type (3) which hence results in the following instantiation of the update rule (4):8 8 Originally, the trust region approach based on (an approximation of) the KL-divergence was motivated in a different way. One can prove that optimizing a certain surrogate objective with the KL-divergence as penalty results in guaranteed monotonous improvement in the expected sum of rewards. See Section 5 for more details.
\begin{equation} \theta = \theta _{k} - D_{k} \nabla m_{k} (\theta _{k}), \label{trpo-update-rule}\tag{11} \end{equation}
with
\[ D_{k} := \frac{\delta}{\sqrt{\nabla m^T_{k} (\theta _{k})
\bar{F}^{- 1}
(\theta _{k}) \nabla m_{k} (\theta _{k})}} \bar{F}^{- 1}, \]
where $\bar{F}$ is the average Fisher information:
\begin{equation} \bar{F} (\theta) := \mathbb{E}_{\pi _{\theta}} [F (\theta, s)] . \label{average-fisher}\tag{12} \end{equation}
4.1 Natural Gradient and TRPO
In the paper that introduced the natural gradient for RL [Kak01N], the above update rule was implemented with a fixed step size multiplying the update direction $\bar{F}^{- 1} (\theta _{k}) \cdot \nabla m_{k} (\theta _{k})$ instead of the adaptive step size coming from the constraint. This choice was already an improvement over the naive policy gradient. The only practical difference between the method introduced in the trust region policy optimization paper [Sch15T] and natural gradient is that the constraint (10) is taken more strictly in TRPO (it will actually be fulfilled with each update) and the step size is not fixed.
The reader might have noticed that in all considerations above we kept silently
ignoring a crucial element of the general trust region optimization algorithm -
namely the possibility to reject an update and to adjust the trust region based
on differences between predicted and actual improvement, steps 4 and 5 in
algorithm (2). Indeed, the natural gradient completely
foregoes these steps, which is precisely why it performs worse than TRPO.
However, what about TRPO itself - is there any rejection of points and region
adjustment happening? In fact, nothing of the like is mentioned in the paper’s
main text. However, in Appendix C, where the implementation details are
described, it is mentioned that a backtracking line search is performed in the
direction $\bar{F}^{- 1} (\theta _{k}) \cdot \nabla m_{k} (\theta _{k})$,
starting from the maximal step size $\frac{\delta}{\sqrt{\nabla m_{k}
\bar{F}^{- 1} \nabla m_{k}}}$, until a sufficient increase in the objective
is observed. This procedure can be understood as a way of rejecting updates and
reducing the trust region if the true increase is too small. The authors also
say that without such a line search, from time to time the algorithm would take
too large steps with catastrophic drops in performance. Such behavior is known
to happen in trust region algorithms where the region is never adjusted, see
[Con00T]. Although part of the general
specification of a trust region algorithm is still not applied in TRPO - namely
comparing predicted and actual improvements and possibly extending the trust
region, not just shrinking it, by following algorithm (2)
more closely than the fixed-size natural gradient updates, the authors of TRPO
introduced a very popular and robust state-of-the-art (at that time) policy
optimization algorithm.9
9 From the point of view presented here, it seems
natural to wonder whether by following the general trust region approach even
more closely and adjusting the trust region based on the same criteria as
described in it, the performance would increase even more (see chapter 6 in
[Con00T] for a slightly stricter but less
general specification of the trust region algorithm).
4.2 Proximal Policy Optimization
The observation that trust region extension and shrinking were not fully applied in TRPO but some version of them was still needed to prevent catastrophic collapse brings us to the next improvement upon TRPO - proximal policy optimization (PPO) [Sch17P]. The main idea here is the following: all we really care about is optimizing the model (8) without taking too large steps in policy space. While using the KL divergence is a natural choice for bounding deviations of general probability distributions, one could make an even more suitable choice that is specific to the actual model of the objective. In the PPO paper this choice can be phrased as following: the new policy is only allowed to improve upon the old one by staying close to it in a pointwise, objective-specific sense, specified in equation (13) below. It is, however, allowed to make large steps in $\theta$ which decrease the expected sum of rewards. This approach is different from the KL-based constraint which is indifferent to whether deviations in a policy lead to an improvement or not. Moreover, the KL-based constraint is based on differences of policies as a whole (as probability distributions), allowing for large pointwise differences.
Denoting
\[ r_{\theta} (a, s) := \frac{\pi _{\theta} (a |s)}{\pi _{k} (a|s)}, \]
the quantity that is to be maximized at the $k$-th iteration is:
\[ \mathbb{E}_{\pi _{k}} [r_{\theta} (a, s) A_{\pi _{k}} (a, s)] . \]
The PPO idea for restricting steps results in the following recipe, for some (small) $\epsilon > 0$ that is chosen as hyperparameter:
- If $A_{\pi _{k}} (a, s) > 0$, then we don’t allow $r_{\theta} (a, s)$ to become larger than $1 + \epsilon$.
- If $A_{\pi _{k}} (a, s) < 0$, then $r_{\theta} (a , s)$ should not become smaller then $1 - \epsilon$.
A very similar behavior can also be implemented as trust-region constraints on $\theta$ of the form
\begin{equation} \operatorname{sign} (A_{\pi _{k}} (a, s)) (r_{\theta} (a, s) - 1) \leqslant \epsilon, \label{ppo-constraints}\tag{13} \end{equation}
where we would have one constraint for each $(a, s )$. However, in the PPO paper these conditions were not included as constraints but rather the objective itself was modified to
\begin{equation} m^{\operatorname{PPO}}_{k} (\theta) := \eta _{\pi _{k}} +\mathbb{E}_{\pi _{k}, t} [\min (r_{\theta} A_{\pi _{k}}, \operatorname{clip} (r_{\theta} A_{\pi _{k}}))], \label{ppo-objective}\tag{14} \end{equation}
where the clip function clips $r$ to $1 \pm \epsilon$ based on the sign of
$A_{\pi _{k}}$ if it is too large or too small. To first order this coincides
with the previous model (8) used in natural gradients and
TRPO. Note that improvements to the objective due to policies too far from $\pi
_{k}$ are cut off, meaning that $m^{\operatorname{PPO}}_{k} (\theta)
\leqslant$$m_{k} (\theta)$. Therefore, the clipped objective can be understood
as a minorant for the unclipped one. Thus, schematically PPO algorithms take
the form:
 Figure 2. Constraining vs.
clipping. Maximizing $m$ w.r.t. the constraint (highlighted region) is almost
equivalent to maximizing the clipped objective $m_{\operatorname{clip}}$
without any constraints by gradient methods, starting from $\theta _{k}$ and
making small steps. As soon as $\theta$ moves into the constrained region,
$\nabla m_{\operatorname{clip}} (\theta)$ vanishes, so e.g. for gradient
ascent with step size $\alpha$, one would violate the constraint by at most
$\alpha \nabla m (\theta^{\ast})$, with $\theta^{\ast}$ being the penultimate
value before convergence of gradient ascent (i.e. sufficiently close to the
constraint boundary).
Figure 2. Constraining vs.
clipping. Maximizing $m$ w.r.t. the constraint (highlighted region) is almost
equivalent to maximizing the clipped objective $m_{\operatorname{clip}}$
without any constraints by gradient methods, starting from $\theta _{k}$ and
making small steps. As soon as $\theta$ moves into the constrained region,
$\nabla m_{\operatorname{clip}} (\theta)$ vanishes, so e.g. for gradient
ascent with step size $\alpha$, one would violate the constraint by at most
$\alpha \nabla m (\theta^{\ast})$, with $\theta^{\ast}$ being the penultimate
value before convergence of gradient ascent (i.e. sufficiently close to the
constraint boundary).
Algorithm 3: PPO-style optimization
Unroll the current policy $\pi _{k}$ in order to estimate
\[ \mathbb{E}_{\pi _{k}, t} [\min (r_{\theta} A_{\pi _{k}}, \operatorname{clip} (r_{\theta} A_{\pi _{k}}))] \]
This may involve batching and different strategies for estimating advantages.
Run gradient ascent in $\theta$ in order to maximize the objective obtained in the previous step, thereby obtaining $\theta _{\max}$.
Set $\theta _{k} \leftarrow \theta _{\max}$ and repeat from step 1.
From a practical point of view, optimizing the original objective (8) with a sufficiently expressive policy $\pi _{\theta}$ and gradient methods while satisfying the constraints (13) is essentially equivalent to optimizing the clipped objective (14), meaning that PPO can be viewed as a trust-region optimization as well. Figure 2 can be helpful to understand this statement.
Optimizing the clipped objective will occasionally lead to slight violations of the constraints. This is because the clipped objective only discourages going into the constrained region and does not strictly enforce it. One can view the clipping strategy as a computationally efficient way to deal with constraints of the type (13).10 10 To the author’s knowledge, the point of view that clipping the objective for gradient-based optimization is essentially equivalent to imposing trust-region constraints, albeit not the same ones as in the TRPO paper, has not been mentioned in the literature. This perspective allows for a more straightforward comparison of PPO and other approaches.
PPO is much simpler than TRPO both conceptually and in implementation, while often equaling or outperforming the latter. Intuitively, this might be due to the much more RL-specific constraints (13) on the steps in $\theta$, compared to the general-purpose KL-divergence based constraint (10). Again, as in previous algorithms, adjustments to the trust region based on predicted vs. actual improvements do not form part of the PPO algorithm and one might reasonably speculate that adjusting $\epsilon$ based on such criteria could lead to further improvements of performance.
5 TRPO from monotonous improvement
The derivation of the TRPO update rule (11) in the original paper [Sch15T] was based on quite a different line of thought from the one presented in Section 4 above. The constraint in average Fisher information (10) was motivated by a proof of monotonic improvement of $\eta _{\pi}$ from optimization of a surrogate objective where the KL-divergence is used as penalty. We will give a brief overview of the ideas and calculations that form the backbone of the original paper.
The following useful identity expresses the rewards of one policy $\tilde{\pi}$ in terms of expectation of advantages of another policy $\pi$:
\begin{equation} \eta _{\tilde{\pi}} = \eta _{\pi} +\mathbb{E}_{\tilde{\pi}} \left[ \sum_{t = 0}^{\infty} \gamma^t A_{\pi} (s_{t}, a_{t}) \right] . \label{policy-diff}\tag{15} \end{equation}
This can be easily proved by observing that
\[ \mathbb{E}_{s_{t,} a_{t} \sim \tilde{\pi} } \mathbb{E}_{\tau _{t}} [V_{\pi} (s_{t + 1})] =\mathbb{E}_{\tilde{\pi}} [V_{\pi} (s_{t + 1})], \]
and using the telescopic nature of the sum $\sum_{t = 0}^{\infty} \gamma^t A_{\pi} (s_{t}, a_{t})$. After some computation, equation (15) can be rewritten in state space as:
\[ \eta _{\tilde{\pi}} = \eta _{\pi} + \sum_{s} \rho _{\tilde{\pi}} (s) \mathbb{E}_{a \sim \tilde{\pi} (s)} [A_{\pi} (s, a)] . \]
One might expect that the state distribution $\rho _{\pi}$ does not change too quickly when $\pi$ is smoothly varied, since even if different actions are taken, the unchanged system dynamics should smooth out the behavior of $\rho _{\pi}$. This intuition is useful for finding good approximations: replacing $\rho _{\tilde{\pi}}$ by $\rho _{\pi}$ in the above expression gives a first order approximation to $\eta _{\tilde{\pi}}$, namely exactly the model $m_{\pi} (\tilde{\pi})$ (8) that we have already used above (where we have also shown that it is truly a first order approximation).11 11 In the TRPO paper this model is called $L_{\pi}$. Now one would hope that finding a new policy $\pi$ that improves the approximation given by $m_{\pi}$ could guarantee an improvement in $\eta _{\tilde{\pi}}$, as long as the improved policy $\pi$ stays within a sufficiently small region around $\tilde{\pi}$. Since the KL-divergence gives a way of measuring proximity of distributions, it is maybe not too surprising that such a bound can be derived using it. One of the central results of the TRPO paper is the following relation:
\[ \eta _{\tilde{\pi}} \geqslant m_{\pi} (\tilde{\pi}) - CD^{\max}_{\operatorname{KL}} (\pi, \tilde{\pi}), \]
where $C$ is a constant depending on $\pi$ and $\gamma$ and
\[ D^{\max}_{\operatorname{KL}} (\pi, \tilde{\pi}) = \max _{s} [D_{\operatorname{KL}} (\pi (\cdot |s), \tilde{\pi} (\cdot |))] . \]
Thus, optimizing $m_{\pi} (\tilde{\pi}) - CD^{\max}_{\operatorname{KL}} (\pi, \tilde{\pi})$ w.r.t. $\tilde{\pi}$ leads to guaranteed improvement in the objective. The term $CD^{\max}_{\operatorname{KL}} (\pi, \tilde{\pi})$ acts as a penalty for moving $\tilde{\pi}$ too far from $\pi$. Now, in practice this penalty leads to too small steps and $D^{\max}_{\operatorname{KL}}$ is difficult to estimate. Therefore, the authors propose to replace $D^{\max}_{\operatorname{KL}}$ by the average KL-divergence and to incorporate the requirement to stay close to $\pi$ in KL-divergence as constraint rather than as penalty. This argumentation leads to the trust-region algorithm that we presented in Section 4.1.
6 Conclusion
The TRPO and PPO papers achieved significant improvements to existing RL optimization methods. The core ideas in both can be summarized as: optimize the discounted sum of rewards through steps that don’t bring you too far away from the previous policy by either enforcing constraints or modifying the objective in a smart way.
While naive policy gradient formulates “too far away” as keeping the update in parameter space $\Delta \theta = \theta - \theta _{k}$ small, in TRPO “too far away” is formulated in a more natural sense for maps from states to probability distributions, i.e. using an approximation to average KL divergence, (12). In PPO “too far away” is defined in an intrinsically RL-like way: by not allowing the approximation to improve the expected sum of advantages through point-wise constraints on $\pi (a|s)$ over all states and actions (equations (13) and (14)). Many of these ideas seem very natural from the point of view of optimization theory [Nes04N], especially of trust region methods [Con00T, Noc06N].
