Our team recently attended the 2022 International Conference on Learning Representations (ICLR, 25th to 29th April 2022). A great amount of new research ideas and articles were presented, and we have decided to summarize all those that caught our attention in a series of paper pills.
Paper pills are a way for us to share interesting papers or projects with the TfL community. Each one is a summary of a publication or a piece of software, with a bit of context, short description of methods, main ideas and key results. They are mainly written for practitioners who want a quick overview of the recent developments but do not have the time to delve into too much detail. Nonetheless, if you are a researcher or feel the need to dig deeper, after reading the pill you should find the main article more accessible.
Importantly, we have primarily focused on areas that are interesting for us and for our industry partners, such as data-centric AI, Probabilistic Programming and Explainability. You can find an overview of our main interests in our series page.
Decision-making
Measuring differences between distributions is highly dependent on the selected metric. For example, a slight score misalignment using the KL-divergence might result in a big difference with the Wasserstein distance. Both metrics are heavily used in NN training and, more problematically, at inference, when critical decisions may be on the line. Comparing Distributions by Measuring Differences that Affect Decision Making tries to fix these issues by designing a new class of divergence metrics using the 60 years old notion of H-entropy. By doing so, it introduces an element of novelty in the classical discipline of statistical decision theory, which has important implications for the ML community.
Interpretability
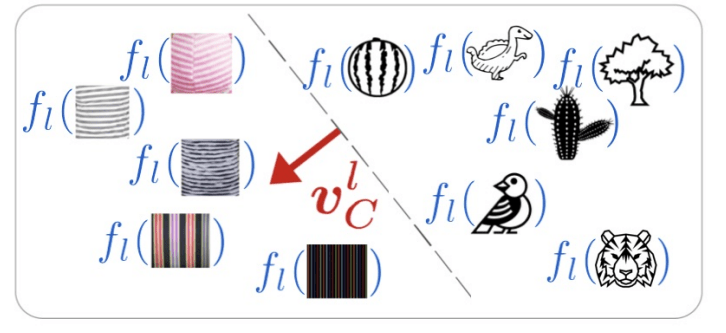 From Testing with Concept Activation Vectors(TCAV)
From Testing with Concept Activation Vectors(TCAV)In one of the first invited talks of the conference, Been Kim argued that interpretability of neural networks is key to engineering our relationship with AI. Among recent work, she highlighted a technique called Testing with Concept Activation Vectors (TCAV) which studies the representational power of NN layers through calculating “directional derivatives” of high level concepts, such as “striped” or “female”.
Neural architecture search
Strides are an important discrete hyperparameter in convolutional neural networks, and changes in them can significantly affect accuracy. Normally, a costly hyperparameter search for the best value would be necessary to reach optimal performance of a CNN. However, the recent paper Learning Strides in Convolutional Neural networks shows how such a value can be learned during training. This is definitely a worthy addition to the toolbox of ML practitioners, saving costly and time-consuming hyperparameter searches.
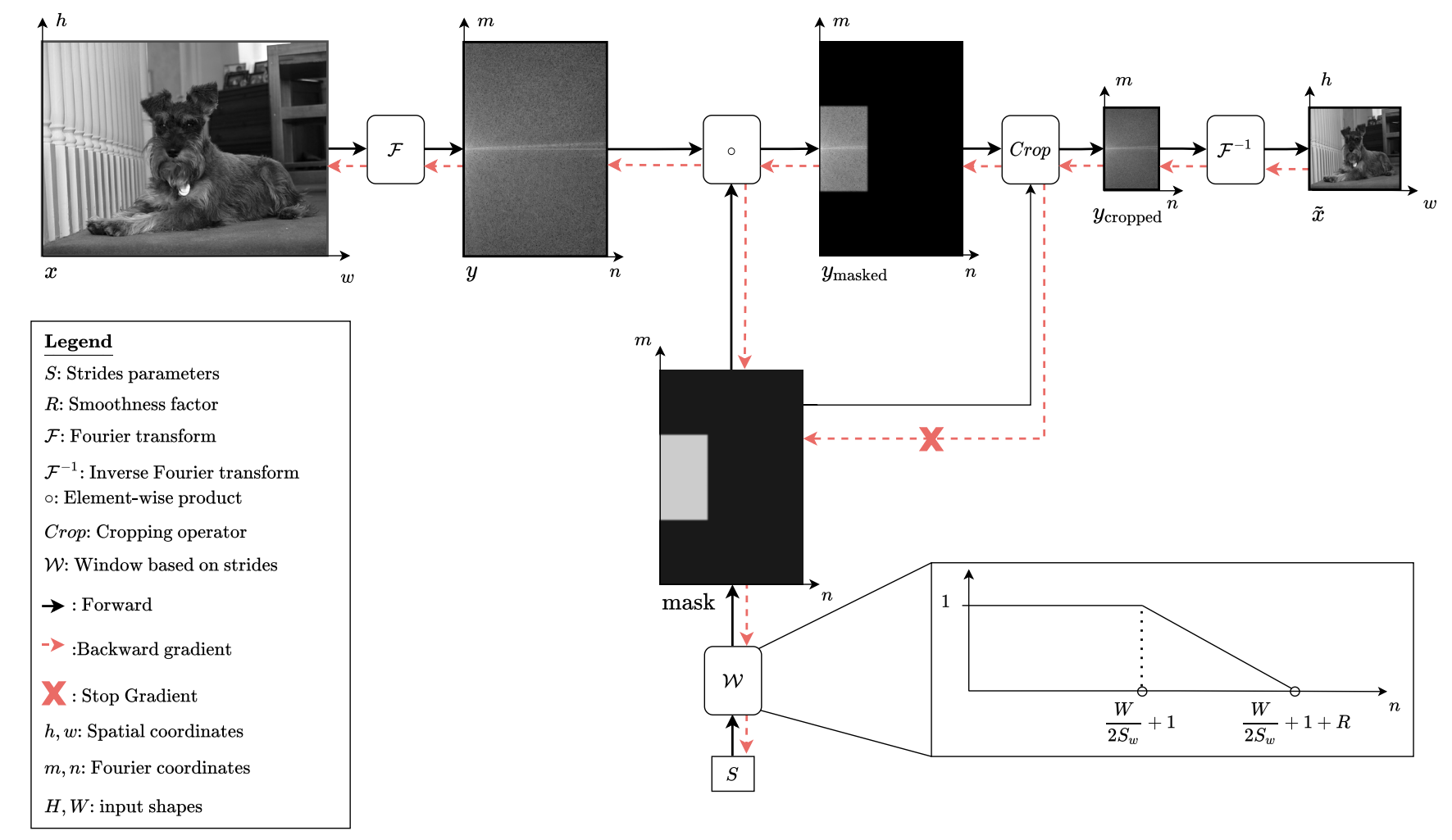 From Learning Strides in Convolutional Neural networks
From Learning Strides in Convolutional Neural networksLabel encodings
Among the most original papers of the conference, Label Encoding for Regression Networks proposes a reformulation of regression that significantly outperforms standard neural network methods. This is done by first quantizing the target into a number of classes, and then encoding those into binary strings. Following earlier work on using classifiers for ordinal regression, the authors show big improvements on standard regression tasks.
Data valuation
Valuation problems in ML can be of different types: for example, feature valuation tries to assess the features that contribute the most to a certain prediction, data valuation investigates which data points are more important in model training, or model valuation estimates which model is more relevant in an ensemble. Considering the importance of shifting from model-centric to data-centric AI, at ICLR we found some interesting studies around Energy-Based Learning for Cooperative Games, with Applications to Valuation Problems in Machine Learning and Resolving Training Biases via Influence-based Data Relabeling.
Diffusion models
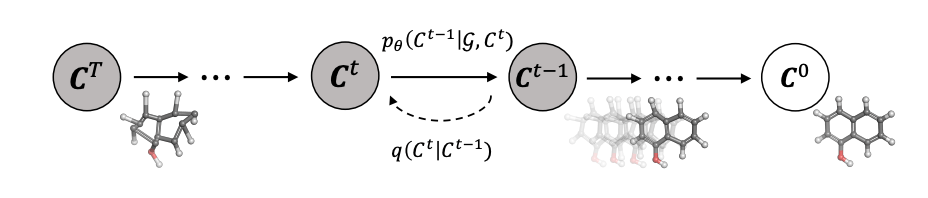 From GeoDiff: A Geometric Diffusion Model for Molecular Conformation Generation
From GeoDiff: A Geometric Diffusion Model for Molecular Conformation GenerationDe-noising diffusion generative models have been a very hot topic in recent months, achieving state-of-the-art results in image and sound generation. The same techniques are now being deployed to tackle problems in other scientific disciplines, such as computational chemistry (GeoDiff: A Geometric Diffusion Model for Molecular Conformation Generation). Nonetheless, despite higher quality of sample generation, diffusion models are known to suffer from slow inference compared to GANs and VAEs. ICLR 2022 has presented many clever solutions to this issue, among which we found most impressive Analytic-DPM: an Analytic Estimate of the Optimal Reverse Variance in Diffusion Probabilistic Models and Progressive Distillation for Fast Sampling of Diffusion Models.
 From Score-Based Generative Modeling through Stochastic Differential Equations
From Score-Based Generative Modeling through Stochastic Differential EquationsAlso intriguing is the work on Score-Based Generative Modeling with Critically-Damped Langevin Diffusion, which, building upon last year’s ICLR paper Score-Based Generative Modeling through Stochastic Differential Equations, presents a new SDE framework for score-based diffusion models, with new state of the art in image generation. For a brief overview of the difference between de-noising diffusion and score-based generative models you can view our recent pill on the subject.
Neural collapse
The phenomenon of neural collapse happens as the training of a neural network on a classification task enters its final stage. In a paper published in 2020 it was observed that, when the classification error on the training set reaches zero but the loss keeps decreasing, the activations of the penultimate layer (evaluated on training data) and the weights of the last (classifying) layer converge to a very simple form, regardless of dataset, network size or training setup. The ICLR 2022 paper Neural Collapse in deep classifiers during Terminal Phase of Training performs a first rigorous analysis of this phenomenon, and, despite not reaching a full mathematical proof, gives a first intuitive and interesting account of how it could emerge.
