Large language models have revolutionised text generation, and programming languages, as well-structured formal languages, are a particularly attractive application domain. Integrated development environments (IDEs) have been automating tedious tasks and providing context-aware assistance functions for many years in order to enhance the developer experience, and LLMs are the next step in the evolution of these assistance functions. With today’s language models, many isolated code generation tasks can already be fully automated, and when writing code, completions and continuations can often be meaningfully inferred from the editing context. Even code-related high-level reasoning tasks (such as code reviews or code understanding) can be partly handled by a language model.
With AutoDev, we present a software package that can provide such functionality via an open-source solution. While you still have the option to draw upon proprietary models (such as OpenAI’s ChatGPT), AutoDev’s primary focus is on custom solutions, enabling the use of open-source models that are optionally fine-tuned to fit your needs and that are hosted locally.
Overview of Assistance Functions
AutoDev currently provides two types of functions:
auto-completion, i.e. inferring completions based on context when editing.
This function is active when typing in the IDE’s editor. It unobtrusively presents suggestions which the user may accept.assistance functions that act on code snippets, which use an instruction-following model to either reason about the code snippet and present the response in a tool window, or to directly apply changes to the respective code snippet.
These functions are executed via a context menu in the IDE, with the respective code snippet selected.
Figure 1 shows AutoDev’s main components and their interactions. Developers interact with the AutoDev plugin through their IDE, which queries the AutoDev inference service.

Figure 1. Structural overview. Developers interact with the IDE plugin, which in turn communicates with the inference service. The inference service either queries a local model (e.g. a fine-tuned open-source model) or a passes the request on to a remote API.
- For auto-completion, the model is served directly by the AutoDev inference service, i.e. the model is always locally provided and is either an unmodified open-source model (from the Hugging Face Hub) or a fine-tuned version of such a model. Fine-tuning may use community or proprietary data.
- For other assistance functions built on instruction-following models, you have the option of using either a (fine-tuned) open-source model, as in the previous case, or a proprietary model such as ChatGPT.
Auto-Completion
The generation of high-quality, context-aware auto-completions is certainly one of the most relevant features. Especially if more than one line can be meaningfully completed (e.g. an entire function body), the development process can be accelerated without the developer having to leave the familiar environment of the IDE’s editor window.
Reasons to Fine-Tune Your Own Model
AutoDev allows the use of a custom model for auto-completions, and there are several reasons why fine-tuning your own model could be a reasonable thing to do:
- Fine-tuning can teach the model about typical usage patterns, in-house libraries and other features of your code that a generic model will not be able to consider. While extended context can sometimes provide enough information, having a model that indeed knows the APIs of your in-house libraries and the associated usage patterns inside and out can be of great value and provide much more relevant suggestions.
- A model that supports the languages in question may not yet exist, and fine-tuning a model that already knows a similar language could prove to be the quickest way to attain one. If you are a using a custom-tailored domain-specific language (DSL) or an obscure language with few public repositories that are appropriately licensed, commercial providers may not be able to cater to your needs.
Furthermore, hosting models yourself alleviates data privacy concerns, as interactions with third parties can be fully avoided.
Filling in the Middle
For auto-completion, we require a model that is able to quickly infer reasonable completions from the context around the cursor within the editing window. Ideally, both the context before the cursor as well as after the cursor are adequately considered in order to produce a completion that appropriately fills in the middle.
Notably, causal language models can be trained to fill in the middle (FIM) by
using special tokens that mark the beginning of the preceding and succeeding
context (prefix and suffix),
with the desired middle part coming last,
thus enabling the use of a causal model for auto-completion
[Bav22E].
Specifically, during training, we simply transform documents into differently
structured documents where the middle part comes last, such that filling in the
middle becomes a next token prediction problem on the transformed document, as
shown in Figure 2.
When generating training data, the middle section (marked) can be selected at
random.
During inference, we provide as input a document that ends with the
<fim-middle> tag based on the context around the cursor,
and the model can produce the desired completion via next token prediction.
Figure 2. FIM transformation. The middle section, which is selected at random for training, is moved to the end, and the three resulting parts are marked via special tokens.
Because editing is an activity where the context is subject to continuous change, we need models to respond quickly. It can therefore be advantageous to use smaller models where inference can be reasonably fast.
Fine-Tuning Experiments
We experimented with fine-tuning in order to determine how hard it is to solve
the perhaps most challenging task of teaching a model an entirely new language.
Specifically, we experimented with the
bigcode/santacoder
model, which intially knew only Python,
Java and JavaScript, applying fine-tuning in order to teach it the languages C#,
Ruby and Rust using the training implementation in the
transformers library.
With its 1.1 billion parameters, the model is moderately sized.
Data for our target languages was taken from the
bigcode/the-stack-dedup
dataset.
Experiments were run on a virtual machine with 8 Intel Broadwell CPU cores,
64 GB of RAM and an Nvidia V100 GPU (32 GB VRAM).
We applied low-rank adaptation (LoRA) [Hu21L] in addition to full parameter fine-tuning in order to validate the claims that even very small adapters can be sufficient for a model to learn new things. In LoRA, only the parameters of a low-rank version of the attention matrices used to map the input token representations to query, key and value representations are trained, while all other parameters remain untouched. This reduces the memory required for parameter updates based on gradient information during training and results in potentially very small representations of model adapters.
In-Context Learning
We found that when applying the original model to auto-completion tasks in one of the new languages, we could sometimes obtain reasonable completions if there was sufficient context available for the model to pick up on. This was especially true for C#, a language that is syntactically close to Java. As shown in Figure 3, the unmodified model was able to generate a completion that is syntactically correct for the given task even though the language was unfamiliar to the model. It is essentially able to “copy” the correct syntax from the prefix context that is given. This is an example of in-context learning.

Figure 3. C# auto-completion generated by the unmodified model. The model is able to generate a syntactically correct completion through in-context learning.
Of course, in-context learning is dependent on all the relevant language-specific aspects being demonstrated in the context and will not scale to more complex examples where in-depth knowledge of the language is required.
Effects of Fine-Tuning Approach and Duration
As a slightly more challenging example, we consider the problem of computing the names of adult employees based on list of employee objects. Unsurprisingly, the unmodified model is unable to generate a correct completion in this case. A lightly fine-tuned model, however, which was trained for a mere 1000 steps, is already capable of producing a correct solution, as shown in Figure 4. For context, a single training step used a batch of 16 text samples to perform a gradient update and took approximately half a minute.

Figure 4. C# auto-completion generated by a lightly fine-tuned model. The solution is correct yet verbose.
As we fine-tune further, we obtain solutions that make use of more advanced, language-specific features, producing very compact, elegant solutions: The completion in Figure 5 uses C#’s more functional language-integrated query syntax (LINQS) to implement the solution.

Figure 5. C# auto-completion generated by a more strongly fine-tuned model. The model is able to leverage its knowledge of the language in order to generate an elegant, compact solution.
The effects of extended fine-tuning can also be evaluated quantitatively. For a causal model, we essentially want to assess the degree of uncertainty when generating text samples from an unseen test set using the model. A common metric that captures this notion is perplexity.1 1 The perplexity is the exponentiated cross-entropy, averaged across all tokens in the test data. In probabilistic terms, the perplexity thus corresponds to the reciprocal value of the geometric mean of the next token probabilities. For example, if the perplexity is 2, then each token in the ground truth documents was generated by the model with probability 1/2 “on average”. Table 1 shows perplexity values for the generation of C# code.
| model | perplexity | |
|---|---|---|
| bigcode/santacoder (base model) | 1.97 | 100% |
| after 2000 fine-tuning steps (full) | 1.84 | 93% |
| after 1000 fine-tuning steps (full) | 1.83 | 93% |
| after 3000 fine-tuning steps (full) | 1.81 | 92% |
| after 4000 fine-tuning steps (full) | 1.79 | 91% |
Because C# and Java are so similar, the perplexity is already rather low to begin with and is not drastically reduced by fine-tuning. The qualitative results do improve significantly with the number of fine-tuning steps, however, as demonstrated above.
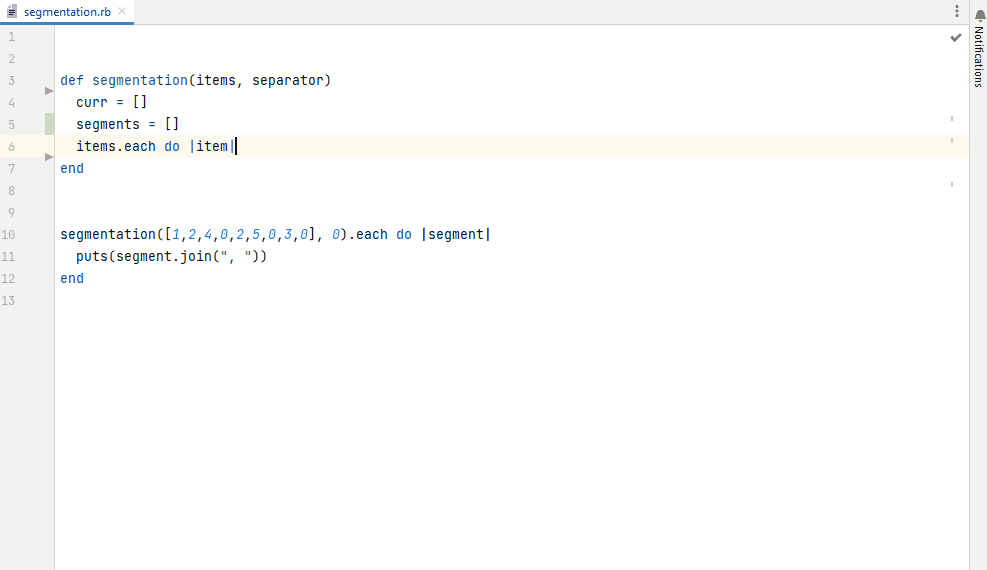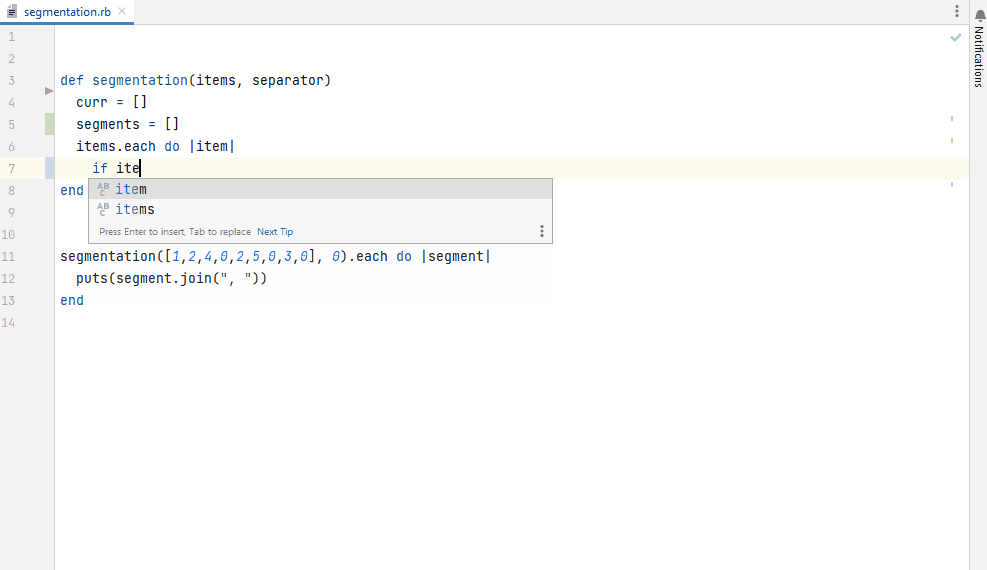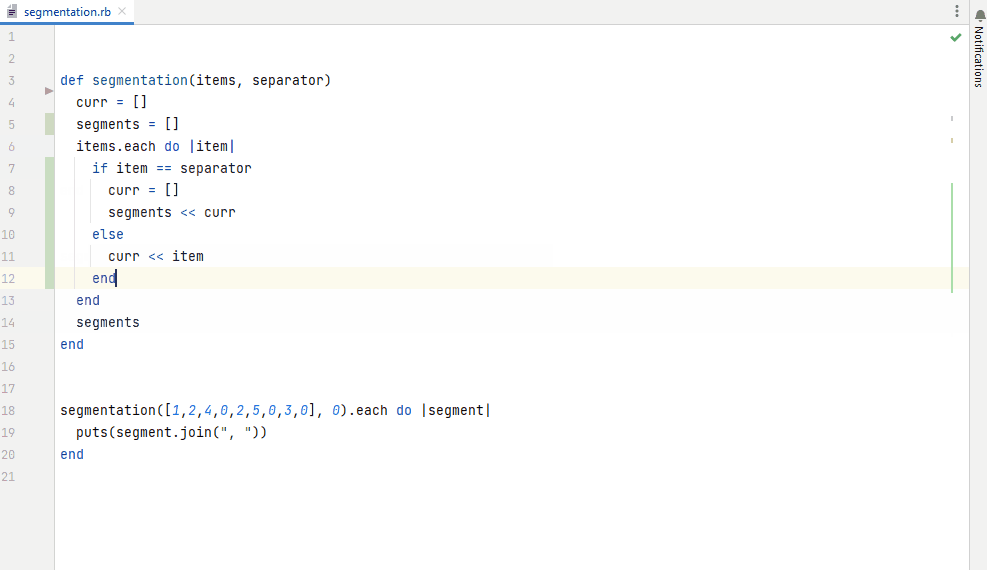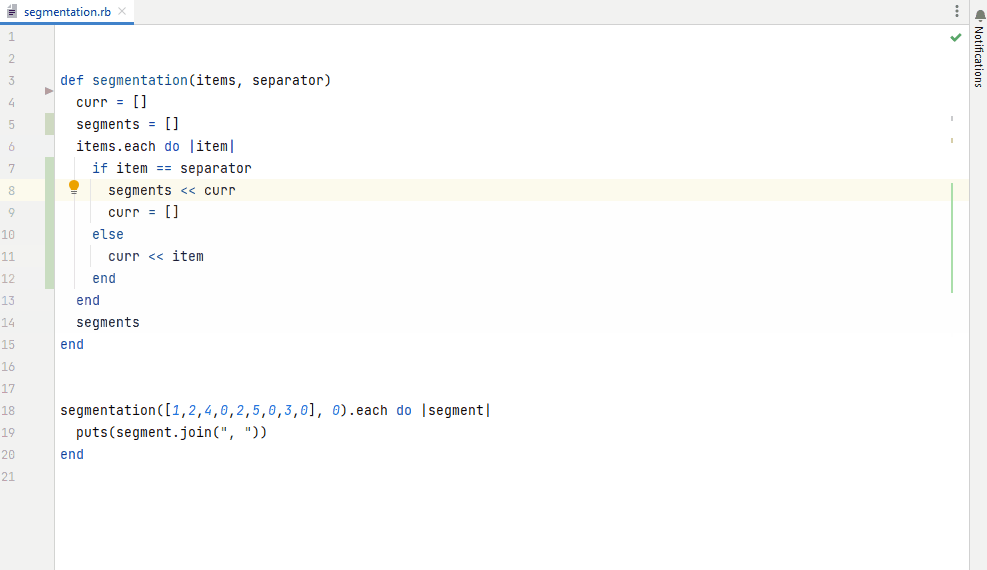
Figure 6. Auto-completion based on a fine-tuned model for Ruby code generation, integrated in IntelliJ IDEA
For languages that differ more greatly from Python, Java and JavaScript, we observe larger perplexity values. Consequently, a larger number of fine-tuning steps is required in order to obtain a model that performs well. Table 2 lists perplexity values for the generation of Ruby code: Perplexity values are larger initially and drop more significantly with fine-tuning. Figure 6 shows the fine-tuned Ruby model in action.
| model | perplexity | |
|---|---|---|
| bigcode/santacoder (base model) | 3.98 | 100% |
| after 3000 fine-tuning steps (LoRA) | 3.40 | 86% |
| after 500 fine-tuning steps (full) | 2.93 | 74% |
| after 3000 fine-tuning steps (full) | 2.80 | 70% |
| after 6000 fine-tuning steps (full) | 2.71 | 68% |
For Ruby, we also applied low-rank adaptation (LoRA) based on the implementation in the PEFT library. Unfortunately, the results are somewhat disappointing: Even after 3000 fine-tuning steps with LoRA, the model’s perplexity was still far from the value achieved by a model that used a mere 500 steps of full parameter fine-tuning. In the listed result, we used rank parameter $r=16$, but we also experimented with values as high as 64 and observed no significant improvement. Furthermore, owing to technical limitations of the trainer implementation, we had to disable gradient checkpointing when using LoRA, rendering any memory savings LoRA may theoretically have been able to achieve void. Making matters worse, the use of LoRA caused numerical issues in torch’s gradient scaler, which we circumvented by using full single precision (fp32) instead of half precision (fp16), further increasing the memory requirements and causing the LoRA-based training process to ultimately use significantly more memory than full parameter tuning with half precision.
The results we obtained for Rust were qualitatively similar to the ones we obtained for Ruby. However, because Rust features some language concepts that are not found in any of the originally supported languages, even heavily fine-tuned models (with training times in excess of one week) were unable to generate good completions for some of the more challenging completion tasks we defined. As the language to be supported via fine-tuning differs more strongly from the languages the base model is familiar with, more and more extensive fine-tuning is required.
Performance Evaluation
Efficient inference being a key concern in practice, we conducted experiments in order to assess the runtime performance and memory requirements of alternative GPU- and CPU-based compute frameworks, including approaches that use quantisation. Specifically, we compare
- the original implementation, using only the transformers library
(
transformers), - the BetterTransformer
model transformation (
bettertransformer), - ONNX Runtime (
onnxruntime), including model variants that use quantisation in conjunction with the advanced vector extensions (AVX) instruction set (avx512).
We consider both CPU- and GPU-based applications of these frameworks
(cpu and gpu), and we furthermore consider model variants that use a
caching mechanism (cached) to ones that do not.
The caching mechanism, which stores intermediate representations of keys and
values in order to reuse them for subsequent token generations, is a standard
feature of the transformers library.
Runtime performance values are summarised in Figure 7.
Unfortunately, none of the CPU-based frameworks come close to GPU-based
inference.
As indicated by the grey connection, the caching mechanism
can result in significant speedups.
Because the use of cached values constitutes an interface change in relation to
the initial token generation (the cached values being provided in an additional
argument), the same mechanism cannot straighforwardly be transferred to
ONNX-based models, as an ONNX export is required to pertain to a single control
flow path.
The ONNX Runtime-based implementations with caching thus use two separate models
(one without cached values and one with cached values).
Unfortunately, the use of two models appears to generate overhead,
which sometimes cannot be amortized by performance gains:
While we do observe a slight speedup in the case of the quantized model that
leverages the AVX instruction set (onnxruntime-cached-avx512-cpu is faster
than onnxruntime-avx512-cpu), the regular CPU-based ONNX Runtime model
actually suffers a slowdown.
Ideally, we would have liked to have observed a speedup similar to the one
marked by the grey connector.2
2
If the main reason for not observing a similar speedup is the use of two models,
there may be a workaround.
Note that it should be possible to use a single control flow path which
initially uses cache tensors that feature a 0-dimension, thus enabling the use
of a single model - albeit not without overriding some internal behaviour within
the existing implementations.
Investigating this option would be an interesting direction for future work.
Community contributions are welcome!

Figure 7. Runtime performance of different inference frameworks
Memory usage results are summarised in Figure 8. The only interesting observation here is that the use of quantized representations in combination with vectorised operations (AVX512 models) - while producing a non-negligible speedup - does not, unfortunately, reduce the total inference memory requirements.

Figure 8. Memory usage of different inference frameworks
Unfortunately, fast and memory-efficient inference, especially on CPUs, is still a challenge. When limited to CPU-based inference, the use of the frameworks and transformations we experimented with are not sufficient in order to reach a level of performance that would be suitable for real-world applications.
Assistance Functions that Act on Code Snippets
In addition to auto-completion, we consider applications of instruction-following models in AutoDev. Given an existing code snippet in the IDE editor window, the user selects a pre-defined assistance function. In the background, a (potentially model-specific) prompt is generated which contains the selected code snippet along with function-specific instructions. The model’s response is streamed to the IDE plugin and either presented in a separate tool window (as in Figure 9) or streamed directly to the editor window (as in Figure 10).
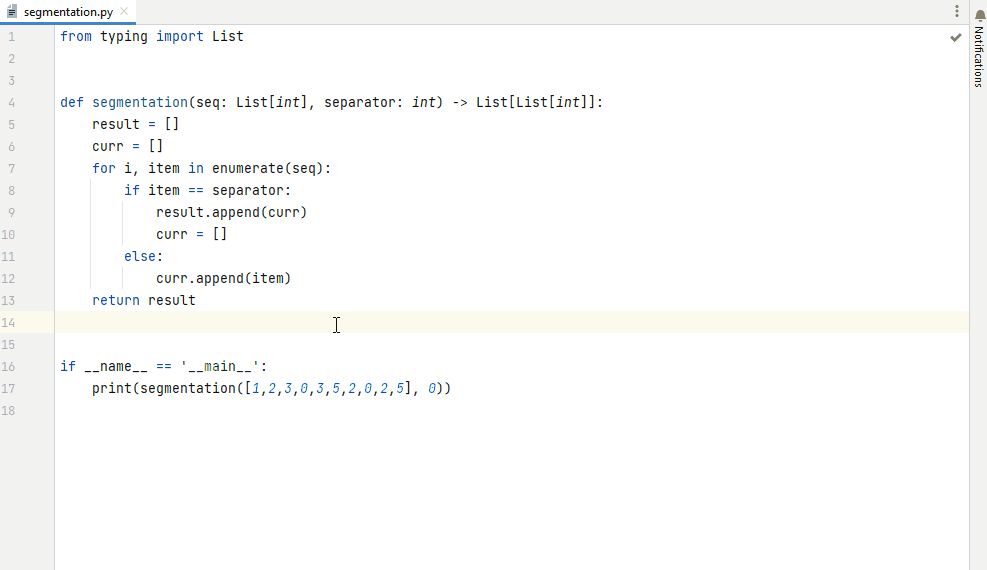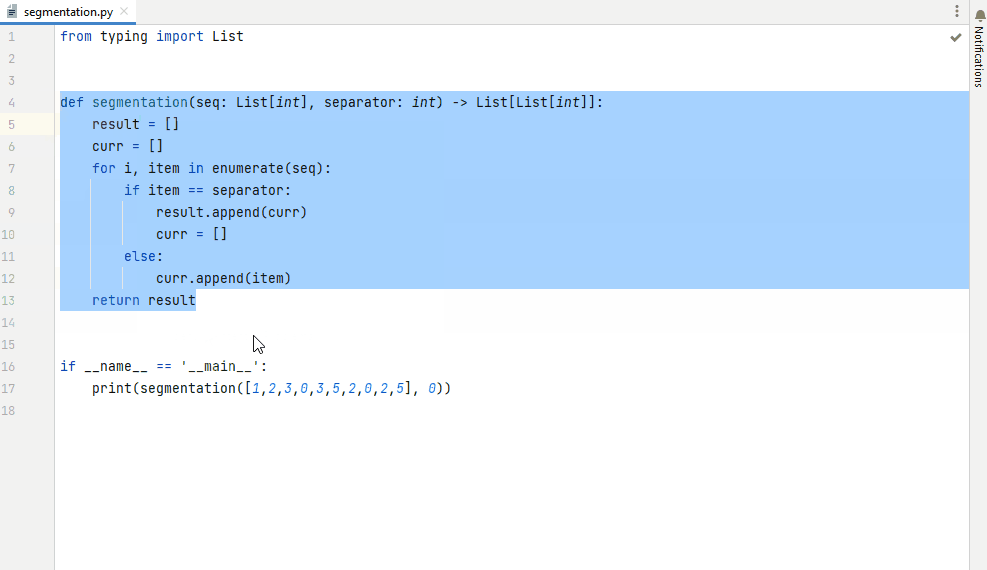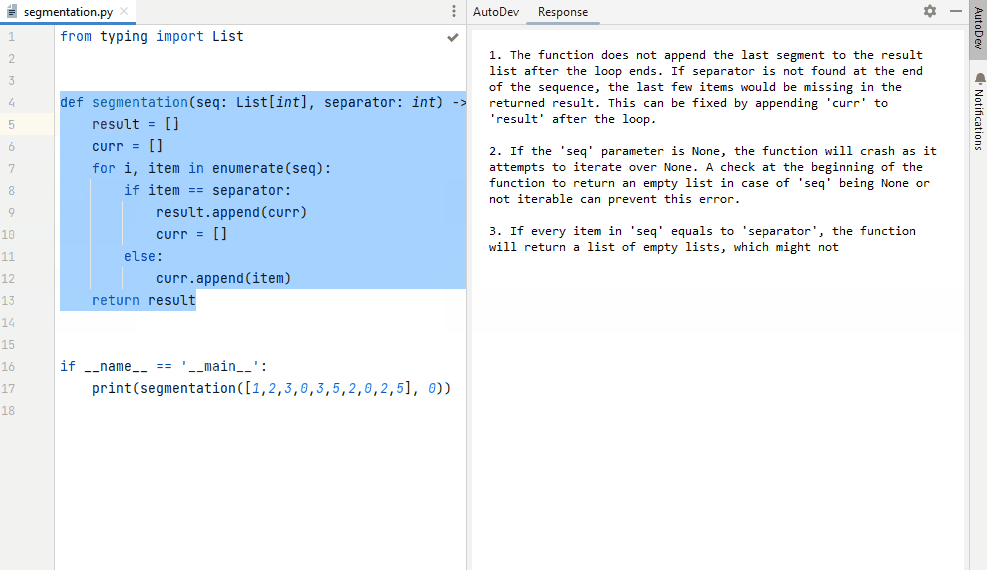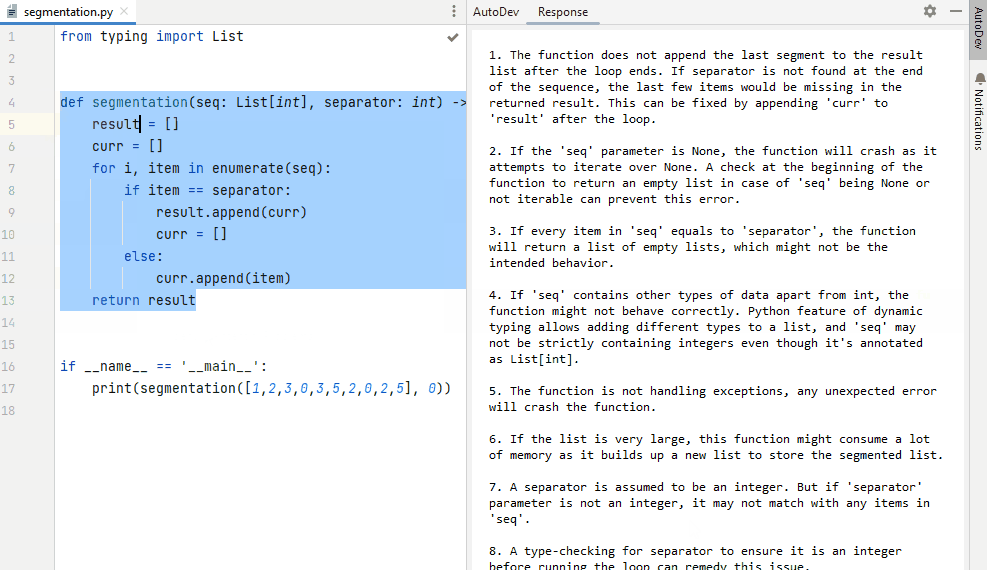
Figure 9. Asking AutoDev to identify potential problems in a piece of code
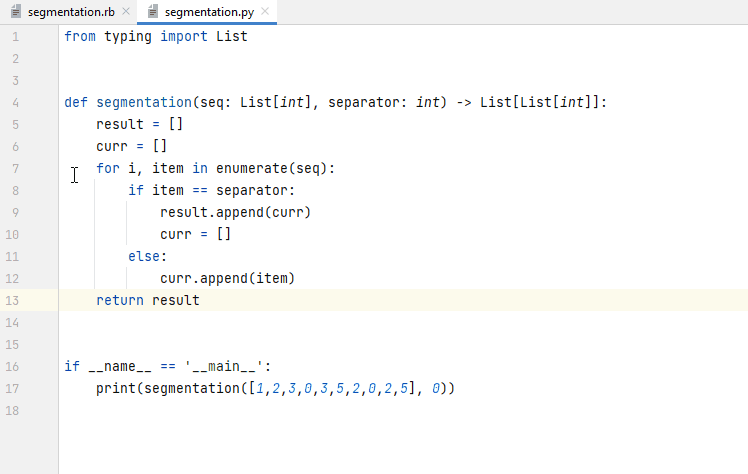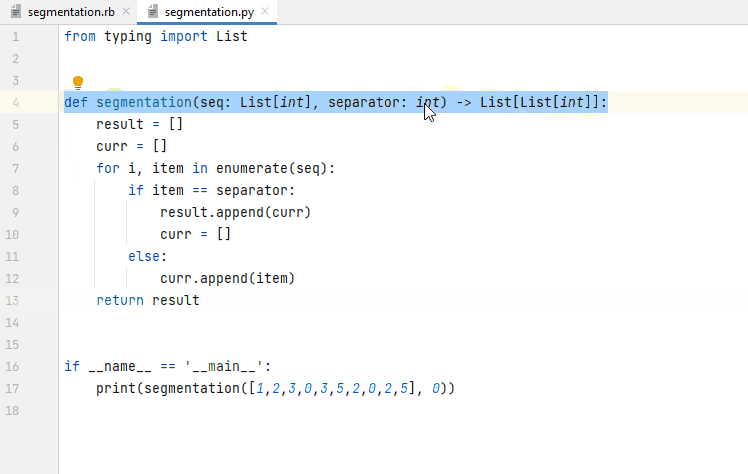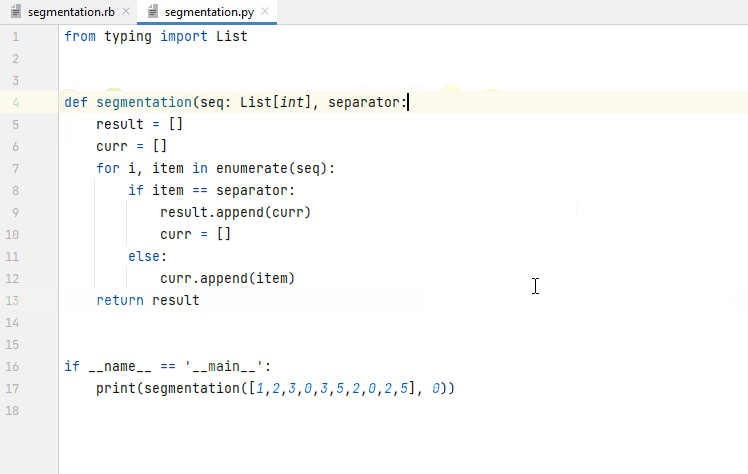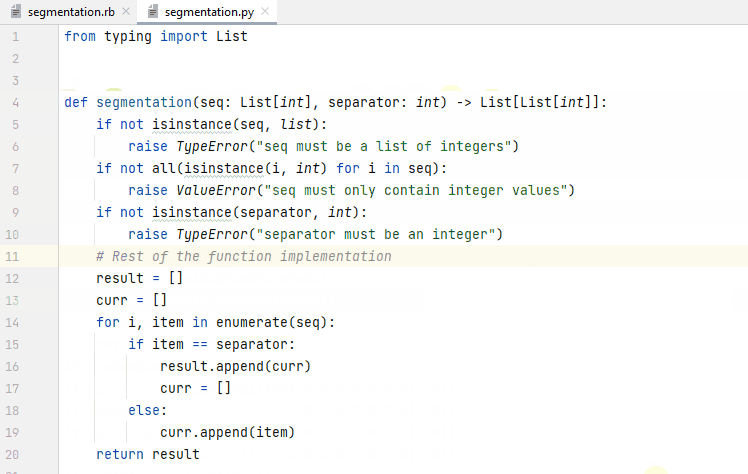
Figure 10. Asking AutoDev to add input checks to a function
In contrast to auto-completion, we support both self-hosted as well as external models for these functions. In the examples presented in this section, we used OpenAI’s API to query GPT-4, but the use of open-source models such as StarCoder is equally possible. Of course, the more powerful the instruction-following model, the more advanced the assistance functions can be. Through the use of streaming, we can tolerate slower response times and therefore are not limited to models that are capable of producing a full response in very short periods of time.
Conclusion
With AutoDev, we have presented a software solution that encompasses the full journey from fine-tuning your own code-based language model to applying it within an integrated development environment. As open-source software, AutoDev can serve as a basis for further experimentation or even provide a starting point for a full-fledged custom code assistant.
